- Introdução a Criação de Temas
- Primeiros Passos, Primeiras Linhas
- Usando uma Imagem
- Informações Básicas do Sistema
- Time e Uptime
- Informações da CPU
- Informações da Memória
- Uso do HD - Aplicação de Gráficos em Barra
- Monitorando o Tráfego da Rede - Aplicação de Gráficos em Linha
- Área de Click
- Considerações Adicionais
- Conclusão
Saturday, November 25, 2006
SuperKaramba: Índice
SuperKaramba: Conclusão
A muito tempo eu queria escrever um manual/guia em português sobre o superkaramba, isso remete a dificuldade que tive de aprender por falta de material disponível.
Sei que os critérios de freqüência de publicação não ajudaram tanto quanto eu pretendia que tivesse ajudado, especialmente porque eu não consegui manter um ritmo de acesso para a publicação. E mesmo tendo parte do material escrito eu não conseguia publicar.
Então, eu resolvi publicar tudo de uma vez e, certamente, isso prejudicou quem acompanhava os posts e se exercitava depois. Mas no fundo, dado a falta de freqüência, foi melhor publicar tudo de uma vez. O índice deve ajudar quem tiver que reler o material inteiro. Esse índice, depois de construído, ficará na sessão de links na barra lateral do blog.
Com esse pequeno guia foi fornecido material para a criação de temas simples, baseado no que existe de mais comum na rede, e para dizer a verdade, do que existe na minha própria área de trabalho, cuja a figura pode ser visualisada abaixo. Todos os temas que criamos foram desenvolvidos a partir dos temas que podem ser vistos no canto esquerdo da imagem.
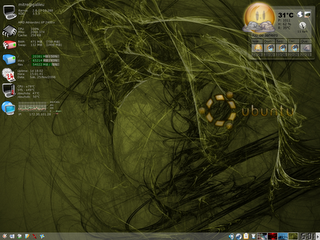
Nessa imagem existem algumas diferenças, exemplo eu tenho três partições e dois HDs. Eu estou usando um tema para monitoramento da temperatura do sistema, da CPU e dos HDs e isso eu não mostrei aqui, não é possível ver que eu posso acionar o kcontrol com um click (óbvio, não?). E no canto direito da imagem, nós podemos ver o Liquid Weather ++ em uso, esse tema (que não fui eu que fiz, que fique claro para os novatos é um dos temas mais usados do mundo e eu considero um dos mais sofisticados que existe.
Passo adicionais serão necessários para que quiser chegar o nível de usar o python, mas muita gente que não conhece o SuperKaramba pode conhecer o python, então, esses passos adicionais podem não ser tão complicados assim. Se é o seu caso, faça isso. O ganho de qualidade é sensível.
Do mais, a série de tópicos sobre o superkaramba termina por aqui.
Technorati Tags: kde superkaramba
Sei que os critérios de freqüência de publicação não ajudaram tanto quanto eu pretendia que tivesse ajudado, especialmente porque eu não consegui manter um ritmo de acesso para a publicação. E mesmo tendo parte do material escrito eu não conseguia publicar.
Então, eu resolvi publicar tudo de uma vez e, certamente, isso prejudicou quem acompanhava os posts e se exercitava depois. Mas no fundo, dado a falta de freqüência, foi melhor publicar tudo de uma vez. O índice deve ajudar quem tiver que reler o material inteiro. Esse índice, depois de construído, ficará na sessão de links na barra lateral do blog.
Com esse pequeno guia foi fornecido material para a criação de temas simples, baseado no que existe de mais comum na rede, e para dizer a verdade, do que existe na minha própria área de trabalho, cuja a figura pode ser visualisada abaixo. Todos os temas que criamos foram desenvolvidos a partir dos temas que podem ser vistos no canto esquerdo da imagem.

Nessa imagem existem algumas diferenças, exemplo eu tenho três partições e dois HDs. Eu estou usando um tema para monitoramento da temperatura do sistema, da CPU e dos HDs e isso eu não mostrei aqui, não é possível ver que eu posso acionar o kcontrol com um click (óbvio, não?). E no canto direito da imagem, nós podemos ver o Liquid Weather ++ em uso, esse tema (que não fui eu que fiz, que fique claro para os novatos é um dos temas mais usados do mundo e eu considero um dos mais sofisticados que existe.
Passo adicionais serão necessários para que quiser chegar o nível de usar o python, mas muita gente que não conhece o SuperKaramba pode conhecer o python, então, esses passos adicionais podem não ser tão complicados assim. Se é o seu caso, faça isso. O ganho de qualidade é sensível.
Do mais, a série de tópicos sobre o superkaramba termina por aqui.
SuperKaramba: Considerações Adicionais
O que eu não falei ?
Não falei de muita coisa. Não falei do python, mas disse que não ia falar logo no primeiro post da série. Não falei de alguns sensores, muito usados, como que interage com xmms e o que obtém informações de temperatura.
Também não mencionei como é feito aqueles temas que parecem 3D, bem, é uma questão de design de background e eu não sou muito bom com design...
Também não comentei várias opções extras que cada sensor ou objeto possuí, mas isso teve uma lógica, eu comentei o que julguei ser mais comum e que apresentasse de forma adequada o objeto ou o sensor. Por exemplo, quando apresentei o sensor da memória eu não comentei que existe uma opção para mostra a memória livre, ao invés da memória usada. Se eu tivesse feito a apresentação de cada opção disponível os tópicos ficariam ainda maiores e muito mais cansativos de serem lidos. Além de ficar muito mais parecido com uma tradução livre de parte do manual.
O que é preciso para ir além ?
O único grande tutorial é a ajuda oficial, ao contrário da maioria dos manuais de ajuda, essa ajuda é muito boa, mas está em inglês. o guia oficial não ajuda muito na imaginação, mas para isso você pode se inspirar em outros temas já feito.
Links
Technorati Tags: kde superkaramba
Não falei de muita coisa. Não falei do python, mas disse que não ia falar logo no primeiro post da série. Não falei de alguns sensores, muito usados, como que interage com xmms e o que obtém informações de temperatura.
Também não mencionei como é feito aqueles temas que parecem 3D, bem, é uma questão de design de background e eu não sou muito bom com design...
Também não comentei várias opções extras que cada sensor ou objeto possuí, mas isso teve uma lógica, eu comentei o que julguei ser mais comum e que apresentasse de forma adequada o objeto ou o sensor. Por exemplo, quando apresentei o sensor da memória eu não comentei que existe uma opção para mostra a memória livre, ao invés da memória usada. Se eu tivesse feito a apresentação de cada opção disponível os tópicos ficariam ainda maiores e muito mais cansativos de serem lidos. Além de ficar muito mais parecido com uma tradução livre de parte do manual.
O que é preciso para ir além ?
- Treine o que apresentei.
- Aprenda a usar os sensores do xmms e de temperatura.
- Aprender shellscript e kdialog, além de ensinar "truques" muito interessantes, fornecerá conhecimento para o dia-a-dia no linux.
- Conhecer bem os recursos dos programas do KDE podem ajudar muito, por exemplo, seria possível criar um interface para usar o K3B a partir de um tema do superkaramba. Alguém fez isso ? Não que eu saiba, mas o K3B suporta DCOP, logo o que mencionei é possível.
- Conhecer os outros programas também. Um exemplo é criar um player usando o mpg123 ao invés do xmms. Isso passa por conhecer shellscript.
- Conhecer design além do mínimo e bom senso, ajuda [bom gosto é relativo, eu sei, mas bom senso não, tem gente que têm e outros que não, exemplo, não coloque fonte branca em fundo claro, nem fonte preta em fundo escuro, isso é bom senso, não é bom gosto (ou falta de), do que adianta fazer um tema sofisticado e não ter como ver o tema na tela ?].
- Aprender python por te levar longe [vide esse tema].
O único grande tutorial é a ajuda oficial, ao contrário da maioria dos manuais de ajuda, essa ajuda é muito boa, mas está em inglês. o guia oficial não ajuda muito na imaginação, mas para isso você pode se inspirar em outros temas já feito.
Links
SuperKaramba: Área de Click
O único objeto não estudado até o momento é a área de click (ou seria clique?). Bem, o exemplo oficial é bem instrutivo. Considere o tema:
É de longe um dos recursos mais visualizado em screenshots pela net. O próximo tópico são as considerações adicionais, coisas que não falei, links que ainda não escrevi, informações úteis que podem ajudar a escrever um tema.
Technorati Tags: kde superkaramba
karamba x=160 y=350 w=50 h=50 interval=1000 locked=trueMuito bem, ao clicar na área do tema o programa "kdialog --msgbox 'CPU load: %v'" será executado. Esse exemplo permite perceber a interação que os sensores podem ter com comandos diversos, mas se quiser algo mais parecido com uma barra de tarefas, considere o tema abaixo:
clickarea x=0 y=0 w=50 h=50 onclick="kdialog --msgbox 'CPU load: %v'" sensor=cpu
karamba x=160 y=350 w=60 h=60 interval=1000 locked=trueO que esse comando faz é executar o kate quando alguém clicar. Lembrando que quando a posição do tema está travada o tema reage com um único click, mas se a posição do tema não estiver travada serão necessários dois cliques.
image x=0 y=5 path="icons/kate.png"
clickarea x=0 y=0 w=60 h=60 onclick="/usr/bin/kate"
É de longe um dos recursos mais visualizado em screenshots pela net. O próximo tópico são as considerações adicionais, coisas que não falei, links que ainda não escrevi, informações úteis que podem ajudar a escrever um tema.
SuperKaramba: Monitorando o Tráfego Rede
Considere que deseja monitorar no mesmo gráfico o tráfego de upload e download da rede. É preciso fazer algumas considerações antes de começar a montar esse tema. Algumas dessas considerações são perguntas, usualmente, fazem parte das configurações de um tema baixado da net.
Primeiro, considere que para distinguir o upload do download cada um terá uma cor diferente. Por isso, usaremos a configuração color onde for necessário. Agora precisamos determinar a interface. Se é ppp (para discada e ASDL, exemplo: ppp0) ou eth (para conexões de rede, exemplo: eth0). Nesse tema consideraremos que a interface é ppp0. Outra pergunta que fica é: qual é a faixa de valores dos downloads ? Nesse tema, configuraremos para um limite máximo de tráfego de 300 KiB/s, não sei se é algo muito comum ou representativo da realidade diversa da internet, mas como é muito fácil adaptar isso eu vou considerar esse valor. O ideal é que seja projetado como um pouco maior do que o volume máximo do tráfego usual que quer monitorar.
Sendo assim, considere o arquivo de tema definido abaixo.
Note uma pequena diferença no valor de h, isso permitirá visualisar as duas linhas, mesmo quando os valores forem iguais (no caso, isso nomalmente só ocorre no zero).
É muito conveniente definir uma legenda. Assim não precisará lembrar ou advinhar o que cada linha representa. Fazemos isso escrevendo com a cor utilizada em cada linha. É apenas um simples texto que tem como único charme uma cor diferente para cada linha.
Só para constar, caso não queira gráficos e prefira texto, pode usar as linhas abaixo. Só não tente adicionar essas linhas no tema acima, elas não combinam muito com o tema apresentado. Elas deveriam ser utilizadas em outro local/tema.
Technorati Tags: kde superkaramba
Primeiro, considere que para distinguir o upload do download cada um terá uma cor diferente. Por isso, usaremos a configuração color onde for necessário. Agora precisamos determinar a interface. Se é ppp (para discada e ASDL, exemplo: ppp0) ou eth (para conexões de rede, exemplo: eth0). Nesse tema consideraremos que a interface é ppp0. Outra pergunta que fica é: qual é a faixa de valores dos downloads ? Nesse tema, configuraremos para um limite máximo de tráfego de 300 KiB/s, não sei se é algo muito comum ou representativo da realidade diversa da internet, mas como é muito fácil adaptar isso eu vou considerar esse valor. O ideal é que seja projetado como um pouco maior do que o volume máximo do tráfego usual que quer monitorar.
Sendo assim, considere o arquivo de tema definido abaixo.
karamba x=160 y=350 w=200 h=60 interval=1000Partindo direto para a parte onde temos um gráfico, temos os seguinte bloco de linhas:
image x=0 y=5 path="icons/network2.png"
# Imagens de escala
image x=55 y=8 path="icons/bg_rede.png"
image x=55 y=18 path="icons/bg_rede.png"
# Gráficos da Rede
graph x=55 y=8 w=88 h=27 color=182,240,182 sensor=network device="ppp0" format="%in" max=300 interval=300
graph x=55 y=8 w=88 h=29 color=240,140,140 sensor=network format="%out" device="ppp0" max=300 interval=300
#Legenda de cores
text x=195 y=34 color=182,240,182 value="-- down"
text x=195 y=41 color=240,140,140 value="-- up"
# Gráficos da RedeA linha começa indicando que se trata de um gráfico de linha com o comando graph, logo depois vem o posicionamento relativo x, y, que já foi extensamente discutido aqui. Depois a duas informações novas que caracteriza o gráfico, são sua largura, w e sua altura, h, essas informações são importantes para definir a área de exposição do gráfico. Em seguida usamos uma distinção de cor entre as duas linhas, no caso é um tipo de cor salmão para o upload e um verde para o download, use as de sua preferência. Depois desse ponto, a explicação se torna particular para esse caso, primeiramente definimos o tipo de sensor, pode ser qualquer um dos disponíveis, mas no caso, usamos o network o sensor network precisa de duas informações, o dispositivo de conexão e o tipo de tráfego monitorado, no caso, indicamos o dispositivo, device, ppp0 e o tipo %in ou %out, eu intencionalmente posicionei os dois em posição contrária, somente para mostrar que ordem não interfere no resultado. depois, voltamos a definições do objeto graph, definindo a escala máxima. Eu implicitamente escolhi o KiB/s, portanto, max é igual a 300, por fim, definimos a taxa de aquisição. Para o monitoramente de rede, pode ser pequena.
graph x=55 y=8 w=88 h=27 color=182,240,182 sensor=network device="ppp0" format="%in" max=300 interval=300
graph x=55 y=8 w=88 h=29 color=240,140,140 sensor=network format="%out" device="ppp0" max=300 interval=300
Note uma pequena diferença no valor de h, isso permitirá visualisar as duas linhas, mesmo quando os valores forem iguais (no caso, isso nomalmente só ocorre no zero).
É muito conveniente definir uma legenda. Assim não precisará lembrar ou advinhar o que cada linha representa. Fazemos isso escrevendo com a cor utilizada em cada linha. É apenas um simples texto que tem como único charme uma cor diferente para cada linha.
#Legenda de coresPor fim, é interessante, apesar de desnecessário, definir uma imagem de fundo para representar uma escala. Eu não sou bom em Design e sofri muito quando fiz isso a muito tempo atrás. Mas no fundo são apenas uma imagem transparente que colocada duas vezes faz a área de exposição ficar dividida em três regiões. No nosso caso, isso combina direitinho porque 300 dividido por 3 é exatamente 100. Pode imaginar o que aconteceria se a escala fosse até 200, não? Ficaria muito difícil ter uma idéia do valor ao olhar a figura. Eu diria que o ideal seria usar uma imagem com uma escala préviamente definida, mas isso dificultaria muito na generalidade. As linhas que definem o fundo do gráfico são:
text x=195 y=34 color=182,240,182 value="-- down"
text x=195 y=41 color=240,140,140 value="-- up"
# Imagens de escalaA imagem bg_rede.png está disponível aqui.
image x=55 y=8 path="icons/bg_rede.png"
image x=55 y=18 path="icons/bg_rede.png"
Só para constar, caso não queira gráficos e prefira texto, pode usar as linhas abaixo. Só não tente adicionar essas linhas no tema acima, elas não combinam muito com o tema apresentado. Elas deveriam ser utilizadas em outro local/tema.
# Velocidade da rede, em formato numéricoBem, com isso terminamos os estudos de gráficos e com esse estudo chegamos quase no fim da série de artigos. Faltam apenas quatro. O próximo ensinará a construir regiões de cliques, depois eu farei considerações adicionais sobre, para explicar o que eu não falarei e como continuar sozinho, e por fim eu farei uma conclusão do estudo. Para fechar o quarto e último tópico será na verdade o primeiro e conterá um índice com links para todos os tópicos, isso deve facilitar muito a vida de todo mundo.
text x=192 y=8 sensor=network device="ppp0" format="%in KiB/s" interval=300
text x=192 y=18 sensor=network device="ppp0" format="%out KiB/s" interval=300
Friday, November 24, 2006
SuperKaramba: Uso do HD com Gráficos em Barra
Primeiramente, apenas para ficar claro, eu considerar apenas um HD, com apenas uma partição montada em /. As imagens utilizadas, bg_disk.png e fon_disk.png estão disponíveis nesse arquivo zip.
Ele é definido apenas em uma linha, essa:
Como vê, usar um gráfico horizontal é muito simples, mais complicado é explicar o motivo de existir a linha abaixo:
Por fim, o tema apresenta a linha:
Por favor, observe o interval=60000 em todas as linhas em lêem informações do HD. É bom não usar um valor muito mais baixo que esse para não sobrecarregar o uso do HD. Francamente eu não tenho informações de problemas ocasionados com o uso inadequado de temas do superkaramba, mas não custa ser razoável, não é ?
O próximo post trará uma aplicação do uso de gráficos em linha, no caso, na obtenção de informações da rede, tráfego de upload e download.
Technorati Tags: kde, superkaramba
karamba x=160 y=350 w=200 h=50 interval=1000Bom, como é um gráfico desses ? Trata-se de um gráfico de barras ... logo, é uma imagem que é redimensionada pelo superkaramba de 0 a 100 % de acordo com a porcentagem de uso do disco. Simples, não?
image x=0 y=0 path="icons/hdd_mount.png"
# Escrendo o rótulo do gráfico
text x=50 y=13 value="/ :"
# Imagens do fundo do grafico em barra
image x=94 y=12 path="icons/bg_disk.png"
# Grafico em barra horizontal
bar x=95 y=13 vertical=false path="icons/fon_disk.png" sensor=disk mountpoint="/" interval=60000
# Texto para ajudar no visual
text x=98 y=13 sensor=disk mountpoint="/" format="%u MiB / %up%" interval=60000
Ele é definido apenas em uma linha, essa:
# Grafico em barra horizontalOu seja, a linha começa com "bar", define se é um gráfico de barras vertical (vertical=true) ou horizontal (vertical=false), continua a linha com o arquivo de imagem indicado. Aí vem a parte que diz qual o sensor movimenta o gráfico, no nosso caso, o sensor é o disk que tem como uma opção obrigatória o ponto de montagem, que nas minhas considerações é apenas o "/" (poderia ser o /home/ ou qualquer outro que deseje).
bar x=95 y=13 vertical=false path="icons/fon_disk.png" sensor=disk mountpoint="/" interval=60000
Como vê, usar um gráfico horizontal é muito simples, mais complicado é explicar o motivo de existir a linha abaixo:
# Imagens do fundo do grafico em barraEu procurei escrever uma definição bem óbvia. "Imagem do fundo do gráfico em barra", isso traz um efeito bonito de se ver, especialmente por causa do deslocamento de 1 px na direção y, entre image e bar. Para que fique claro, é apenas uma questão estética.
image x=94 y=12 path="icons/bg_disk.png"
Por fim, o tema apresenta a linha:
text x=98 y=13 sensor=disk mountpoint="/" format="%u MiB / %up%" interval=60000Essa linha não está relacionada com o gráfico de barras, ao contrário, ela simplesmente escreve um texto com informações do uso do disco e do tamanho total do disco. Um tema alternativo, sem o gráfico, teria apenas essa linha, nesse tema, ela ajuda o visual.
Por favor, observe o interval=60000 em todas as linhas em lêem informações do HD. É bom não usar um valor muito mais baixo que esse para não sobrecarregar o uso do HD. Francamente eu não tenho informações de problemas ocasionados com o uso inadequado de temas do superkaramba, mas não custa ser razoável, não é ?
O próximo post trará uma aplicação do uso de gráficos em linha, no caso, na obtenção de informações da rede, tráfego de upload e download.
SuperKaramba: Informações da Memória
Depois de uma longa pausa, eu espero conseguir terminar o conjunto de artigos sobre o superkaramba.
Um dos sensores mais utilizados em temas é o que obtém a memória utilizada do sistema. Considere o tema abaixo.
Eu poderia colocar, para que fique mais claro, que o caracter % indica o que é uma opção do sensor, o resto é texto simple, ou seja, se tiver a memória RAM toda de 1 GiB, ao utilizar format="[%tm MiB]" parecerá no lugar format="[1024 MiB]".
De forma bem simples, o tema acima escreve a memória em primeiro e a memória total em seguida. Diversas opções poderiam ser utilizadas para fornecer a mesma informação com um formato diferente, mas aqui ficaremos apenas com essas.
[Eliminando - O texto abaixo é instrutivo, mas inútil]
Um problema comum de quem usa o superkaramba é a definição de memória RAM em uso. É comum essa informação ser igual a memória total, e o usuário é levado a acreditar que, de fato, a memória total está sendo consumida. Isso não é verdade. Ocorre que a especificação de memória em uso segue as regras do comando free. Se digitar free -m verá informações sobre memória em usada, memória livre e lá no fim, o que eu traduziria como memória cache. É nela que está a chave da questão, a memória realmente em uso no sistema (por programas que estão aberto) é igual a memória total subtraída da memória livre e da memória cache. Antes que alguém crucifique essa história, me permita afirmar que as considerações do comando free -m tem lógica e que não devem ser consideradas um erro. Eu não pretendo explicar isso aqui, mas do ponto de vista de um servidor essa lógica é excepcional, do ponto de vista de um desktop é que (do meu ponto de vista pessoal) não faz muito sentido se apegar as essas definições.
Para contornar isso eu uso um script, esse script calcula a exata quantidade de memória que está realmente em uso.
Assim, a linha:
[/Eliminando]
[update]
Acabei de descobrir sobre o %umb, o "b" adicionado faz com o que o sensor não considere a memória cache (e o buffer). O que está acima continua sendo verdade porque eu me referia ao %um usado no texto, mas é desnecessário, apesar de possível, usar o script atualmente. Foi uma mosca bem grande :-(.
[/update]
Os textos posteriores terão como foco a criação de gráficos dinâmicos. Começando pelo gráfico em barras para determinar o uso do HD.
Technorati Tags: kde superkaramba
Um dos sensores mais utilizados em temas é o que obtém a memória utilizada do sistema. Considere o tema abaixo.
karamba x=160 y=350 w=200 h=50 interval=1000A essa altura eu espero que o tema acima não esteja muito difícil de entender. Concentrando-se na parte realmente diferentes, temos o sensor memory utilizado com duas opções, a m e s, m para memória RAM e s para a memória swap. De cada tipo de memória está sendo obtido duas informações, a primeira que usa o sufixo u é a memória em uso e a segunda opção, com o sufixo t, trata a memória total.
image x=0 y=0 path="icons/memory_mount.png"
# Escrevendo texto
text x=50 y=10 value="RAM:"
text x=50 y=20 value="Swap:"
# Obtendo informações da memória RAM
text x=90 y=10 sensor=memory format="%um MiB"
text x=140 y=10 sensor=memory format="[%tm MiB]" align=right"
# Obtendo informações da memória swapp
text x=90 y=20 sensor=memory format="%us MiB"
text x=140 y=20 sensor=memory format="[%ts MiB]" align=right"
Eu poderia colocar, para que fique mais claro, que o caracter % indica o que é uma opção do sensor, o resto é texto simple, ou seja, se tiver a memória RAM toda de 1 GiB, ao utilizar format="[%tm MiB]" parecerá no lugar format="[1024 MiB]".
De forma bem simples, o tema acima escreve a memória em primeiro e a memória total em seguida. Diversas opções poderiam ser utilizadas para fornecer a mesma informação com um formato diferente, mas aqui ficaremos apenas com essas.
[Eliminando - O texto abaixo é instrutivo, mas inútil]
Um problema comum de quem usa o superkaramba é a definição de memória RAM em uso. É comum essa informação ser igual a memória total, e o usuário é levado a acreditar que, de fato, a memória total está sendo consumida. Isso não é verdade. Ocorre que a especificação de memória em uso segue as regras do comando free. Se digitar free -m verá informações sobre memória em usada, memória livre e lá no fim, o que eu traduziria como memória cache. É nela que está a chave da questão, a memória realmente em uso no sistema (por programas que estão aberto) é igual a memória total subtraída da memória livre e da memória cache. Antes que alguém crucifique essa história, me permita afirmar que as considerações do comando free -m tem lógica e que não devem ser consideradas um erro. Eu não pretendo explicar isso aqui, mas do ponto de vista de um servidor essa lógica é excepcional, do ponto de vista de um desktop é que (do meu ponto de vista pessoal) não faz muito sentido se apegar as essas definições.
Para contornar isso eu uso um script, esse script calcula a exata quantidade de memória que está realmente em uso.
Assim, a linha:
text x=90 y=10 sensor=memory format="%um MiB"é substituída por:
text x=90 y=10 sensor=program program="echo $(~/bin/memoria) MiB"onde o conteúdo do arquivo ~/bin/memoria é:
#!/bin/shAntes que me pergunte, a resposta é sim, é possível colocar a linha em questão diretamente no tema. Eu é que não faço isso.
echo "`free | grep Mem | awk '{printf (\"%.0f\", ( $3 -($6 + $7) )/1000)}'`"
[/Eliminando]
[update]
Acabei de descobrir sobre o %umb, o "b" adicionado faz com o que o sensor não considere a memória cache (e o buffer). O que está acima continua sendo verdade porque eu me referia ao %um usado no texto, mas é desnecessário, apesar de possível, usar o script atualmente. Foi uma mosca bem grande :-(.
[/update]
Os textos posteriores terão como foco a criação de gráficos dinâmicos. Começando pelo gráfico em barras para determinar o uso do HD.
De novo o Google Reader
Na verdade, agora é apenas uma narração de fatos que ocorreram no últimos dias.
No dia 20 eu publiquei um tópico comparando o Bloglines com o Google Reader e colocando motivos para minha migração apesar de alguns problemas que eu apontei no Google Reader. No dia 23 boa parte desses problemas tinham sido "corrigidos", vide update no mesmo tópico, acrescentando novos recursos. Durante o acréscimo de novos recursos eles corrigiram problemas de compatibilidade com o IE7, hoje durante essa madrugada esses recursos foram removidos, motivo: problemas com o IE6.
A história toda, que vai desde quais foram as modificações feitas até o anúncio da remoção dos recursos, pode ser vista nesse tópico do grupo de discussão do Google Labs - Reader.
Minha esperança é que as novas funcionalidades que melhoraram tanto o desempenho do Google Reader realmente estejam de volta na próxima semana.
Deixo as conclusões para quem quiser tirar conclusões, apesar de eu compreender perfeitamente o ponto de vista dos desenvolvedores do Google Reader, francamente, estou furioso com isso e acho que não preciso explicar o motivo.
Technorati Tags: google rss software:online web2.0
No dia 20 eu publiquei um tópico comparando o Bloglines com o Google Reader e colocando motivos para minha migração apesar de alguns problemas que eu apontei no Google Reader. No dia 23 boa parte desses problemas tinham sido "corrigidos", vide update no mesmo tópico, acrescentando novos recursos. Durante o acréscimo de novos recursos eles corrigiram problemas de compatibilidade com o IE7, hoje durante essa madrugada esses recursos foram removidos, motivo: problemas com o IE6.
A história toda, que vai desde quais foram as modificações feitas até o anúncio da remoção dos recursos, pode ser vista nesse tópico do grupo de discussão do Google Labs - Reader.
Minha esperança é que as novas funcionalidades que melhoraram tanto o desempenho do Google Reader realmente estejam de volta na próxima semana.
Deixo as conclusões para quem quiser tirar conclusões, apesar de eu compreender perfeitamente o ponto de vista dos desenvolvedores do Google Reader, francamente, estou furioso com isso e acho que não preciso explicar o motivo.
Thursday, November 23, 2006
Linha do Tempo das Distribuições Linux
Clique na figura para melhor visualização.

[update]
Eu acho que corrigi o código que fez um belo estrago no design do Planeta GNU/Linux Brasil. Sorry!
[/update]
Technorati Tags: linux história

[update]
Eu acho que corrigi o código que fez um belo estrago no design do Planeta GNU/Linux Brasil. Sorry!
[/update]
Tuesday, November 21, 2006
Screenshots do Google Reader
Comentei sobre a melhora no visual do Google Reader no último post devido ao uso de um "script" stylish, o Google Reader Optimized, bem, aqui estão duas comparações visuais do Google Reader com e sem o Google Reader Optimized.
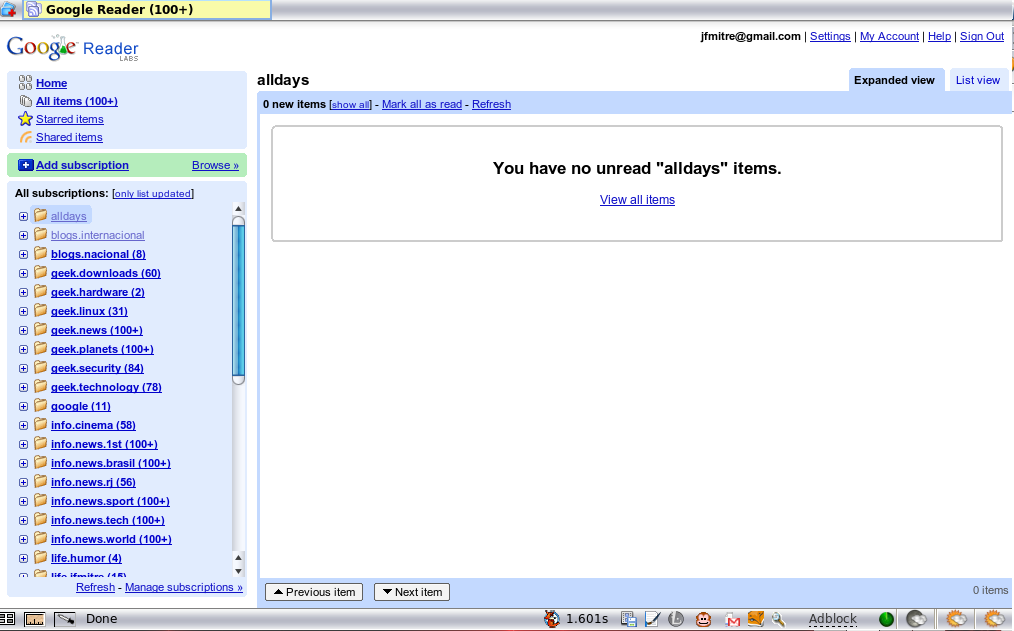
Clique nas imagens para ampliar. Primeiro sem o Google Reader Optimized.

Agora com o Google Reader Optimized.

Eu escrevi algumas observações na segunda imagem, mas não deu para escrever tudo. Assim, vou repetir aqui e completar as principais mudanças.
Technorati Tags: google rss software:online web2.0
Clique nas imagens para ampliar. Primeiro sem o Google Reader Optimized.
Agora com o Google Reader Optimized.
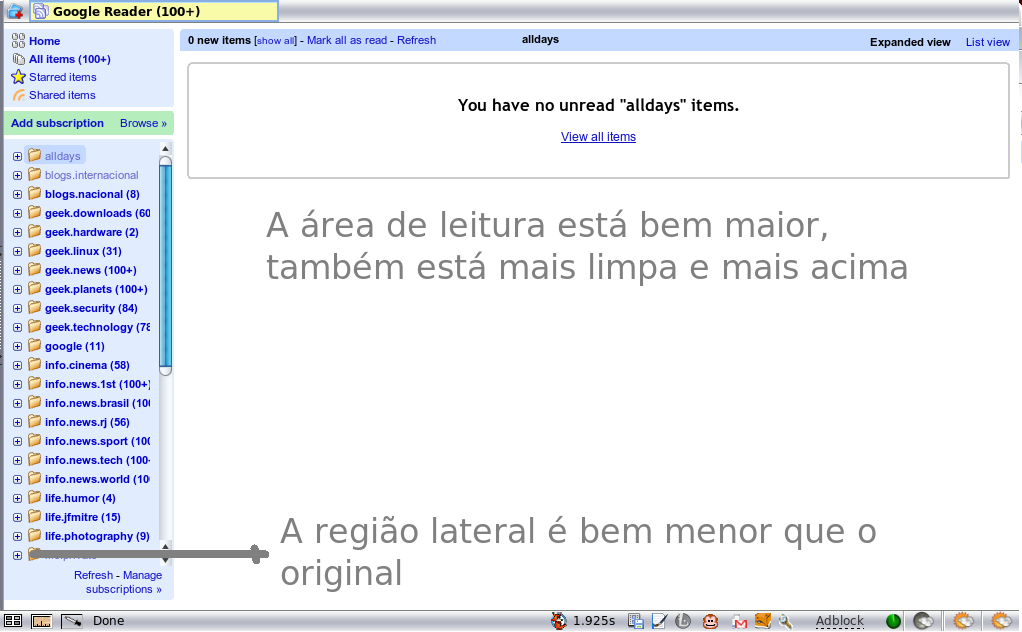
Eu escrevi algumas observações na segunda imagem, mas não deu para escrever tudo. Assim, vou repetir aqui e completar as principais mudanças.
- A primeira e a mais fácil de perceber, a área ativa "subiu", ela está mais acima e permite maior área visual. Ela é fácil de perceber porque o e-mail e o logo do Google Reader desaparecem.
- A mudança que eu considero fundamental é o aumento da largura da região de leitura dos posts. Ela aumente mais ou menos 100 pixels. Com isso, ocorre a diminuição da região de labels, pode reparar que diminuí de forma perceptível, mas pelos menos eu não acho que atrapalhe.
- A terceira e última mudança não pode ser percebida nessas imagens, referem-se a barra que acompanha post a post permitindo adicionar/remover "estrelas", compartilhar, mandar por e-mails, marcar como lida e editar as tags. Bem, essa é a parte que eu não gostei, essa barra em vai para a direta (veja nessa imagem), isso prejudica na hora de editar as tags a cada post (na verdade impossibilita, uma vez que o balão de edição sai da tela). Mas não tem problema, porque se ao colocar o script original não gostar da posição, é só recorrer a página do script que eu adicionei um comentário que menciona como colocar ela de volta na região esquerda do post. Só para ficar registrado nesse blog, basta editar o script e onde estiver escrito .entry-actions { float:right !important; } substitua o right por left ficando .entry-actions { float:left !important; }
Monday, November 20, 2006
Google Reader versus Bloglines
Não deu. Esse último final de semana foi a gota d'água ! O Bloglines (pelo menos a minha conta) ficou inacessível por quase 48 horas. E, como resultado, eu migrei para o Google Reader.
Em primeiro lugar, sou obrigado a reconhecer que o bloglines possuí uma característica única, a possibilidade de compartilhar os blogs em forma de blogroll, com esse visto aqui no meu blog. Isso, exatamente como o fornecido pelo bloglines, eu não conheço lugar que tenha, pelo menos não ainda.
Apesar de eu gerar o blogroll da minha conta do Bloglines, eu não publico aqui todos os feeds que assino, assim, mesmo que ninguém perceba, eu tenho mais ou menos 600 feeds assinados. Isso, por si só, já me dava muita dor de cabeça com o bloglines, mas como dizer, com essa quantidade de feeds, quase todos são lentos. De qualquer forma eu não recomendaria o bloglines a ninguém que tenha mais de 300 feeds e tenha pressa na leitura, apesar que recentes alterações no sistema melhoram essa parte significativamente.
O mais antigo dos problemas (que eu conheço) é uma incompatibilidade com alguns feeds de excelentes blogs como o Meio Bit e BrPoint. Seria ridículo, da minha parte, parar de ler os blogs por causa do software que eu uso para isso. Mas eu ia levando. Afinal, não é tão incomodo assim, mesmo com aumento progressivo de blogs com feeds que apresentam esse problema de compatibilidade.
Nesse meio tempo, as imagens começaram a ter problemas no Bloglines, elas simplesmente não apareciam em alguns feeds, principalmente do Blogger. E eu que acompanho blogs de fotografias (não estão no blogroll) sempre tinha trabalho dobrado. Mas eu ia levando...
Mas aí veio outro problema, alguns feeds, não estavam sendo localizados pelo bloglines, na verdade isso só aconteceu duas vezes até o momento e eu não prestei muita atenção no motivo/característica, mas eram apenas dois, e de baixo volume publicação, então eu coloquei no live bookmark do firefox.
Bom, aí veio o final de semana. Francamente. Foi a gota d'água. Depois do Bloglines ter me deixado feliz com a idéia de ter uma nova funcionalidade (os playlist, que basicamente "simulam" as tags múltiplas, não são tags, mas funcionam como se fossem) o sistema fica fora do ar. E não foi a primeira vez. Volta e meia o "encador" do Bloglines aparece no lugar do site propriamente dito. Só que dessa vez foi a última. Ou quase ...
A primeira opção na minha lista de substitutos é o Google Reader. Depois de sua última atualização eu já tinha experimentado só por curiosidade e até tinha gostado, mas deixei de lado. Agora migrei de vez.
A principal característica que chama atenção do Google Reader são as tags. Não sei se foi o google que "criou" essa filosofia, mas certamente foi ele que popularizou (principalmente devido ao gmail), juntamente com o del.icio.us a idéia de classificar conteúdo com tags.
A começar a importação do opml do Bloglines me deu muitos problemas. Primeiro porque os espaços não são permitidos nas tags, segundo porque o formato do opml do bloglines não parece ser o que o Google Reader "gosta mais". Assim, eu importei o opml no Akregator, modifiquei o que tinha que modificar, acertei tudo e exportei para outro opml que, esse sim, foi muito bem importado pelo Google Reader.
Depois foi só aproveitar os recursos, certo ? Errado. Não sei se já tentou manipular as tags do Google Reader, mas se tentou descobriu que isso (hoje) não é possível. Você não pode renomear uma tag. Só pode deletar ou criar. Até aí, como dizer, é diferente (do gmail), mas é possível. Mas tente gerenciar uma página com 600 links (nos caso a lista dos feeds inscritos) e verá como é demorado. Resultado. Não consegui corrigir o que eu queria no Google Reader. Tive que abrir o Akregator novamente e corrigir o erro que tinha no nome de algumas tags, e repetir o processo de exportar e importar. Algumas interações depois (eu errei mais de uma coisa !), algumas horas depois (3 horas, para ser preciso) lutando contra a lentidão do Google Reader e meus próprios erros (principalmente), eu finalmente consegui ter o que tinha no Bloglines. E segui a vida.
Não demorou muito eu eu tive mais um feed para guardar (eu tenho sempre uma novidade para acrescentar!). Tá, o Firefox 2 e o Bookmarklet do Google Reader funcionam diretinho (até com aqueles dois excluídos mencionados acima, lembra deles ?), mas demora .... ooooo.... naquele momento eu cheguei a conclusão que o pior do Google Reader é se inscrever em um novo feed. Usando o Bookmarklet ou o Firefox 2, não existe a possibilidade de adicionar a tag no momento da inscrição... isso é um absurdo que eu espero que não demore a ser corrigido [Já foi, vide update abaixo] . A única [Não é mais a única] forma de adicionar o feed dentro de uma tag no momento que se inscreve é quando usa o "Add subscription" ou se adiciona através dos diretórios de feeds. Bom, é possível editar as tags do texto que está lendo agora, mas não é possível acrescentar um feed inteiro dentro da tag, a menos que entre no modo de "gerenciamento" do Google Reader, que é o tal que com 600 feeds e é lento de dá dó... então... eu tomei uma medida drástica.
[update - 23/11/2006]
Certas coisas são, tão ... como dizer ... improdutivas (para ser educado) que são rapidamente corrigidas. A que citei acima foi corrigida. Agora é possível trocar o diretório de qualquer feed a qualquer momento usando o "Feed Actions" que aparece acima no canto superior direito da tela ao lado do título do Feed selecionado, antes só era possível desinscrever. Isso é muito, mas muito prático mesmo. Faz o processo de se inscrever em um novo feed seja muito mais produtivo e muito mais rápido, já que não é mais preciso entrar no "gerenciador de feeds" para adicionar o novo feed em um diretório.
[/update - 23/11/2006]
Não dá mais para usar o Bloglines para ler. Os problemas ficaram demais. Passou dos limites do aceitável (e olha que dá pena escrever isso, eu realmente gosto do Bloglines, mas é verdade, infelizmente), principalmente porque existe um agregador online similar, que é exatamente o Google Reader; mas o Google Reader ainda apresenta características desagradáveis na hora de inscrever-se em um feed novo. Então, agora eu uso o Bloglines para inscrever, exporto o opml, importo no Google Reader e tenho o novo feed dentro do novo sistema já com as tags nos seus devidos lugares. Tá, eu sei, isso é muito, mas muito 'idiota' ... mas é muito mais rápido, mas muito mesmo. O processo é um absurdo, mas plenamente justificável pela velocidade (até porque eu posso me inscrever em 5, 6 feeds pela velocidade de quem manipula uma tag).
Para isso eu tive que criar uma nova conta no Bloglines (sim, porque eu ainda uso o Bloglines para publicar o blogroll no blog, ano que vem eu mudo isso juntamente com a atualização do layout) e não me livrarei de dois problemas que reclamo acima, o primeiro do excesso de horas fora do ar e segundo de alguns feeds que não são reconhecidos no bloglines. Mas suas conseqüências já não são tão graves. Primeiro porque eu posso criar opml até no live bookmarks e depois seguir o mesmo processo, só não faço isso por comodidade do hábito, mas se necessário eu farei. Segundo porque se o bloglines sair do ar por um dia, o impacto na minha forma de ver a internet não será tão significativo.
Mas ainda existia um problema. Eu senti a tela pequena para ler. Demorei um bocado com essa sensação desagradável até olha uma dica no home do Google Reader, um "script" stylish, o Google Reader Optimized
Agora, eu tenho no Google Reader a mesma experiência de conforto na leitura que tinha no Bloglines, mas sem os inúmeros problemas que viam se acumulando ao longo do tempo, e que eu ignorava. Bastou dois dias lendo sem ver a mesma notícia repetida 10 vezes no dia, para eu perceber como o problema era grande. E assim, o Bloglines deixou de ser o meu número 1.
Links adiconais:
Technorati Tags: web2.0 google rss software:online
Em primeiro lugar, sou obrigado a reconhecer que o bloglines possuí uma característica única, a possibilidade de compartilhar os blogs em forma de blogroll, com esse visto aqui no meu blog. Isso, exatamente como o fornecido pelo bloglines, eu não conheço lugar que tenha, pelo menos não ainda.
Apesar de eu gerar o blogroll da minha conta do Bloglines, eu não publico aqui todos os feeds que assino, assim, mesmo que ninguém perceba, eu tenho mais ou menos 600 feeds assinados. Isso, por si só, já me dava muita dor de cabeça com o bloglines, mas como dizer, com essa quantidade de feeds, quase todos são lentos. De qualquer forma eu não recomendaria o bloglines a ninguém que tenha mais de 300 feeds e tenha pressa na leitura, apesar que recentes alterações no sistema melhoram essa parte significativamente.
O mais antigo dos problemas (que eu conheço) é uma incompatibilidade com alguns feeds de excelentes blogs como o Meio Bit e BrPoint. Seria ridículo, da minha parte, parar de ler os blogs por causa do software que eu uso para isso. Mas eu ia levando. Afinal, não é tão incomodo assim, mesmo com aumento progressivo de blogs com feeds que apresentam esse problema de compatibilidade.
Nesse meio tempo, as imagens começaram a ter problemas no Bloglines, elas simplesmente não apareciam em alguns feeds, principalmente do Blogger. E eu que acompanho blogs de fotografias (não estão no blogroll) sempre tinha trabalho dobrado. Mas eu ia levando...
Mas aí veio outro problema, alguns feeds, não estavam sendo localizados pelo bloglines, na verdade isso só aconteceu duas vezes até o momento e eu não prestei muita atenção no motivo/característica, mas eram apenas dois, e de baixo volume publicação, então eu coloquei no live bookmark do firefox.
Bom, aí veio o final de semana. Francamente. Foi a gota d'água. Depois do Bloglines ter me deixado feliz com a idéia de ter uma nova funcionalidade (os playlist, que basicamente "simulam" as tags múltiplas, não são tags, mas funcionam como se fossem) o sistema fica fora do ar. E não foi a primeira vez. Volta e meia o "encador" do Bloglines aparece no lugar do site propriamente dito. Só que dessa vez foi a última. Ou quase ...
A primeira opção na minha lista de substitutos é o Google Reader. Depois de sua última atualização eu já tinha experimentado só por curiosidade e até tinha gostado, mas deixei de lado. Agora migrei de vez.
A principal característica que chama atenção do Google Reader são as tags. Não sei se foi o google que "criou" essa filosofia, mas certamente foi ele que popularizou (principalmente devido ao gmail), juntamente com o del.icio.us a idéia de classificar conteúdo com tags.
A começar a importação do opml do Bloglines me deu muitos problemas. Primeiro porque os espaços não são permitidos nas tags, segundo porque o formato do opml do bloglines não parece ser o que o Google Reader "gosta mais". Assim, eu importei o opml no Akregator, modifiquei o que tinha que modificar, acertei tudo e exportei para outro opml que, esse sim, foi muito bem importado pelo Google Reader.
Depois foi só aproveitar os recursos, certo ? Errado. Não sei se já tentou manipular as tags do Google Reader, mas se tentou descobriu que isso (hoje) não é possível. Você não pode renomear uma tag. Só pode deletar ou criar. Até aí, como dizer, é diferente (do gmail), mas é possível. Mas tente gerenciar uma página com 600 links (nos caso a lista dos feeds inscritos) e verá como é demorado. Resultado. Não consegui corrigir o que eu queria no Google Reader. Tive que abrir o Akregator novamente e corrigir o erro que tinha no nome de algumas tags, e repetir o processo de exportar e importar. Algumas interações depois (eu errei mais de uma coisa !), algumas horas depois (3 horas, para ser preciso) lutando contra a lentidão do Google Reader e meus próprios erros (principalmente), eu finalmente consegui ter o que tinha no Bloglines. E segui a vida.
Não demorou muito eu eu tive mais um feed para guardar (eu tenho sempre uma novidade para acrescentar!). Tá, o Firefox 2 e o Bookmarklet do Google Reader funcionam diretinho (até com aqueles dois excluídos mencionados acima, lembra deles ?), mas demora .... ooooo.... naquele momento eu cheguei a conclusão que o pior do Google Reader é se inscrever em um novo feed. Usando o Bookmarklet ou o Firefox 2, não existe a possibilidade de adicionar a tag no momento da inscrição... isso é um absurdo que eu espero que não demore a ser corrigido [Já foi, vide update abaixo] . A única [Não é mais a única] forma de adicionar o feed dentro de uma tag no momento que se inscreve é quando usa o "Add subscription" ou se adiciona através dos diretórios de feeds. Bom, é possível editar as tags do texto que está lendo agora, mas não é possível acrescentar um feed inteiro dentro da tag, a menos que entre no modo de "gerenciamento" do Google Reader, que é o tal que com 600 feeds e é lento de dá dó... então... eu tomei uma medida drástica.
[update - 23/11/2006]
Certas coisas são, tão ... como dizer ... improdutivas (para ser educado) que são rapidamente corrigidas. A que citei acima foi corrigida. Agora é possível trocar o diretório de qualquer feed a qualquer momento usando o "Feed Actions" que aparece acima no canto superior direito da tela ao lado do título do Feed selecionado, antes só era possível desinscrever. Isso é muito, mas muito prático mesmo. Faz o processo de se inscrever em um novo feed seja muito mais produtivo e muito mais rápido, já que não é mais preciso entrar no "gerenciador de feeds" para adicionar o novo feed em um diretório.
[/update - 23/11/2006]
Não dá mais para usar o Bloglines para ler. Os problemas ficaram demais. Passou dos limites do aceitável (e olha que dá pena escrever isso, eu realmente gosto do Bloglines, mas é verdade, infelizmente), principalmente porque existe um agregador online similar, que é exatamente o Google Reader; mas o Google Reader ainda apresenta características desagradáveis na hora de inscrever-se em um feed novo. Então, agora eu uso o Bloglines para inscrever, exporto o opml, importo no Google Reader e tenho o novo feed dentro do novo sistema já com as tags nos seus devidos lugares. Tá, eu sei, isso é muito, mas muito 'idiota' ... mas é muito mais rápido, mas muito mesmo. O processo é um absurdo, mas plenamente justificável pela velocidade (até porque eu posso me inscrever em 5, 6 feeds pela velocidade de quem manipula uma tag).
Para isso eu tive que criar uma nova conta no Bloglines (sim, porque eu ainda uso o Bloglines para publicar o blogroll no blog, ano que vem eu mudo isso juntamente com a atualização do layout) e não me livrarei de dois problemas que reclamo acima, o primeiro do excesso de horas fora do ar e segundo de alguns feeds que não são reconhecidos no bloglines. Mas suas conseqüências já não são tão graves. Primeiro porque eu posso criar opml até no live bookmarks e depois seguir o mesmo processo, só não faço isso por comodidade do hábito, mas se necessário eu farei. Segundo porque se o bloglines sair do ar por um dia, o impacto na minha forma de ver a internet não será tão significativo.
Mas ainda existia um problema. Eu senti a tela pequena para ler. Demorei um bocado com essa sensação desagradável até olha uma dica no home do Google Reader, um "script" stylish, o Google Reader Optimized
Agora, eu tenho no Google Reader a mesma experiência de conforto na leitura que tinha no Bloglines, mas sem os inúmeros problemas que viam se acumulando ao longo do tempo, e que eu ignorava. Bastou dois dias lendo sem ver a mesma notícia repetida 10 vezes no dia, para eu perceber como o problema era grande. E assim, o Bloglines deixou de ser o meu número 1.
Links adiconais:
- Google Reader - http://www.google.com/reader/
- Bloglines - http://www.bloglines.com
- Wikipédia > OPML - http://en.wikipedia.org/wiki/OPML
Friday, November 17, 2006
Novas funcionalidades do Blogger
Realmente algumas das funcionalidades do novo blogger são realmente muito bem vindas.
Eu criei um blog chamado "Testando Recursos" esse blog NÃO TERÁ ATUALIZAÇÕES. Ele existe apenas para literalmente servir de base de testes para mim nessa nova plataforma, permitindo exemplificar alguns dos novos recursos que listo abaixo.
- RSS dos comentários,
- Sistema de categorias com RSS por categoria,
- Histórico muito mais dinâmico,
- Permite adicionar RSS externo ao meu blog (veja o BR-Linux no Testando Recursos)
- Permite melhor gerenciamento de imagens.
- A forma de programar a interface deixou de ser via html e passou a ser via interface gráfica. É claro que não dá para ver isso olhando para o Blog, mas a interface criada é realmente muito fácil de gerenciar e ainda permite editar o código.
Bom, porque, por enquanto, esse blog não contará com alguns desses recursos ?
Simples, não é possível adicionar um RSS externo (por exemplo) sem atualizar o código. E ao atualizar o código eu perco tudo que adicionei durante esses anos, ou seja, gasta tempo para ter o mesmo visual e isso é algo que eu não tenho no momento. Devo atualizar o código do blog no final do ano ou no início de 2007.
Do mais, eu diria que o simples fato de permitir um melhor gerenciamento de imagens (que antes ficavam irremediavelmente perdidas) e de existir a possibilidade de adicionar um RSS por categorias sem qualquer tipo de perda significativa no design ou sem qualquer problema com atualizações externas (exemplo, pedir para todo mundo mudar o endereço, isso pode ser muito chato se não tiver domínio no servidor) faz com que a atualização seja muito interessante.
Eu criei um blog chamado "Testando Recursos" esse blog NÃO TERÁ ATUALIZAÇÕES. Ele existe apenas para literalmente servir de base de testes para mim nessa nova plataforma, permitindo exemplificar alguns dos novos recursos que listo abaixo.
- RSS dos comentários,
- Sistema de categorias com RSS por categoria,
- Histórico muito mais dinâmico,
- Permite adicionar RSS externo ao meu blog (veja o BR-Linux no Testando Recursos)
- Permite melhor gerenciamento de imagens.
- A forma de programar a interface deixou de ser via html e passou a ser via interface gráfica. É claro que não dá para ver isso olhando para o Blog, mas a interface criada é realmente muito fácil de gerenciar e ainda permite editar o código.
Bom, porque, por enquanto, esse blog não contará com alguns desses recursos ?
Simples, não é possível adicionar um RSS externo (por exemplo) sem atualizar o código. E ao atualizar o código eu perco tudo que adicionei durante esses anos, ou seja, gasta tempo para ter o mesmo visual e isso é algo que eu não tenho no momento. Devo atualizar o código do blog no final do ano ou no início de 2007.
Do mais, eu diria que o simples fato de permitir um melhor gerenciamento de imagens (que antes ficavam irremediavelmente perdidas) e de existir a possibilidade de adicionar um RSS por categorias sem qualquer tipo de perda significativa no design ou sem qualquer problema com atualizações externas (exemplo, pedir para todo mundo mudar o endereço, isso pode ser muito chato se não tiver domínio no servidor) faz com que a atualização seja muito interessante.
Blog transferido para a nova versão do blogger
Finalmente.
Depois de ter decidido que iria transferir o blog para a nova versão do blogger e de ter me frustrado com isso, agora eu consegui.
Existe uma lista razoável de novas utilidades que justificam essa mudança, por hora eu digo apenas duas: feeds de comentários e sistema de categorias
Com o primeiro todos vão poder acompanhar eventuais respostas a alguns comentários que eu normalmente escrevo no meu próprio blog e com o segundo eu vou poder disponibilizar feeds por categorias. Essa última, pode me ajudar a cumprir um 'velho' sonho e é o real motivo dessa atualização agora.
Um fato é que não deveria existir nenhum problema. Caso alguém identifique alguma coisa, por favor, faça a gentileza de me informar. Eu agradeço. Tão logo eu me acostume novamente com o ambiente eu volto com uma publicação mais regular de posts.
Depois de ter decidido que iria transferir o blog para a nova versão do blogger e de ter me frustrado com isso, agora eu consegui.
Existe uma lista razoável de novas utilidades que justificam essa mudança, por hora eu digo apenas duas: feeds de comentários e sistema de categorias
Com o primeiro todos vão poder acompanhar eventuais respostas a alguns comentários que eu normalmente escrevo no meu próprio blog e com o segundo eu vou poder disponibilizar feeds por categorias. Essa última, pode me ajudar a cumprir um 'velho' sonho e é o real motivo dessa atualização agora.
Um fato é que não deveria existir nenhum problema. Caso alguém identifique alguma coisa, por favor, faça a gentileza de me informar. Eu agradeço. Tão logo eu me acostume novamente com o ambiente eu volto com uma publicação mais regular de posts.
Thursday, November 16, 2006
Tentativa frustada de atualização do blogger
Depois de uma tentativa frustrada de atualização da versão Blogger, eu devo permanecer com essa versão mesmo até segunda ordem.
Technorati Tags: aviso
Sunday, November 12, 2006
Web 3.0
A web 2.0 ainda surpreende o povão, mas a web 3.0 já é pensada nos bastidores desde quando serviços como blogs, o YouTube ou o MySpace se tornaram febre mundial. São fatos razoavelmente bem compreendidos de que a web 1.0 é a que você lê e a web 2.0 é aquele onde você lê e escreve. Mesmo que essa seja uma visão muito, mas muito simples e limitada do todo.
Apesar de ser uma novidade, existem vários textos que podem ser encontrados com o Google sobre a web 3.0, inclusive em português. Todos os textos ainda são conjecturas, como esse meu texto que você lê. Mas hoje eu encontrei uma visão "de escrever" sobre a web3.0 que realmente me agradou. Infelizmente esse link é restrito aos assinantes do UOL, mas quem puder ler, clique aqui, vale apena, mesmo que não concorde com tudo que está escrito lá.
[update]
Acabei de descobrir, o texto original parece ter livre acesso.
[/update]
Tenho certeza de que encontrará textos técnicos e visões mais interessantes sobre o assunto em outros lugares, mas a visão humana que pode ser observada nesse texto é muito interessante.
Em um dos exemplos, o mais interessante na minha opinião, ele coloca a seguinte questão: "Estou à procura de um local quente para passar as férias e disponho de US$ 3 mil. Ah, e tenho um filho de 11 anos". No dia que a internet conseguir gerar uma resposta eficiente a frase completa colocada acima, nós teremos entrado na web 3.0.
É evidente que nós podemos localizar um local para passar as férias, mas a frase acima não tem muito sentido nos "search engines" de hoje. A internet não compreende a semântica, muito menos idéias completas e esse será o próximo desafio. O mínimo que a internet faz hoje é classificar a qualidade por sistemas como 'page rank', mas isso é muito pouco para esse salto.
Bom, nesse contexto, eu posso pensar apenas em uma coisa: a web 3.0 será muito mais importante para a internet do que está sendo hoje a web 2.0. Isso, é claro, não diminuí a importância da web 2.0, muito pelo contrário ela é crucial para o próximo passo, apenas enaltecesse a importância da geração futura, a próxima geração dará uma salto que nos permitirá diferenciar a qualidade da informação algo que hoje nós não conseguimos com eficiência e generalidade suficientes.
Technorati Tags: web3.0
Apesar de ser uma novidade, existem vários textos que podem ser encontrados com o Google sobre a web 3.0, inclusive em português. Todos os textos ainda são conjecturas, como esse meu texto que você lê. Mas hoje eu encontrei uma visão "de escrever" sobre a web3.0 que realmente me agradou. Infelizmente esse link é restrito aos assinantes do UOL, mas quem puder ler, clique aqui, vale apena, mesmo que não concorde com tudo que está escrito lá.
[update]
Acabei de descobrir, o texto original parece ter livre acesso.
[/update]
Tenho certeza de que encontrará textos técnicos e visões mais interessantes sobre o assunto em outros lugares, mas a visão humana que pode ser observada nesse texto é muito interessante.
Em um dos exemplos, o mais interessante na minha opinião, ele coloca a seguinte questão: "Estou à procura de um local quente para passar as férias e disponho de US$ 3 mil. Ah, e tenho um filho de 11 anos". No dia que a internet conseguir gerar uma resposta eficiente a frase completa colocada acima, nós teremos entrado na web 3.0.
É evidente que nós podemos localizar um local para passar as férias, mas a frase acima não tem muito sentido nos "search engines" de hoje. A internet não compreende a semântica, muito menos idéias completas e esse será o próximo desafio. O mínimo que a internet faz hoje é classificar a qualidade por sistemas como 'page rank', mas isso é muito pouco para esse salto.
Bom, nesse contexto, eu posso pensar apenas em uma coisa: a web 3.0 será muito mais importante para a internet do que está sendo hoje a web 2.0. Isso, é claro, não diminuí a importância da web 2.0, muito pelo contrário ela é crucial para o próximo passo, apenas enaltecesse a importância da geração futura, a próxima geração dará uma salto que nos permitirá diferenciar a qualidade da informação algo que hoje nós não conseguimos com eficiência e generalidade suficientes.
Saturday, November 11, 2006
Rec6 e a novidade que não é mais tão nova assim!
Após ler a análise do ilustre Bruno Alves sobre o estado atual do Rec6, recém-saído da fase beta ... é você deve ter lido essa frase inicial no BR-Linux, tudo bem, eu me conformo em chegar tarde com a notícia, mas não posso deixar de divulgar...
O Rec6 é um sistema nacional similar ao internacional Digg.com, ou seja, um clip de notícias que possuí um excelente nível de tópicos. Nos últimos dois dias (mais ou menos, tá? Na verdade eu vi isso ontem, vide a data do post do Bruno, mas considerando a madrugada, etc e tal...) eu tive mais notícias interessantes "que eu não procurei, mas gostei de ter recebido" chegando no meu leitor de feeds do que nas últimas duas semanas.
Só para deixar claro, chamo de "notícias interessantes que eu não procurei, mas gostei de ter recebido" todas aquelas notícias que a eu não pensava que existiam, de fontes de qualidade que eu não conhecia, de pessoas que eu nunca tinha lido. E além dessas notícias novas e de qualidade eu ainda vi as notícias que eu já tinha lido e/ou vi em algum blog, até notícias do meu blog já passaram por lá, mas essas, como dizer, eu já esperava. O que me impressionou não foram as notícias em si, quem lê mais de 350 feeds não é facilmente surpreendido com novidades, mas os excelentes textos de diversos autores (nacionais e internacionais) que eu nunca tinha lido e que eu provavelmente só descobriria depois que alguém "monitorado" fizesse um link para o site deles.
Para dar um exemplo, veja esse link: 30 Social Bookmarks 'Add to' footer links for blogs
Nesse texto tem uma coleção absurda de sistemas 'Add to' para você adicionar no seu blog. Eu estava procurando por isso a dias, mas eu sequer sabia o nome "desses negócios", quero dizer: eu nunca realizaria uma busca decente no google sem conhecer o mínimo do que procuro. O resultado pode ser visto aqui mesmo, ou melhor, no meu blog mesmo (quem estiver lendo do planeta precisa abrir o blog para ver a novidade), acrescentei nele uma barra para facilitar a vida de quem quiser adicionar o conteúdo desse blog no seu bookmark social ou no seu clip de notícias preferido. E claro, o primeiro da lista (da esquerda para a direita) é o Rec6!
Technorati Tags: rec6 clip notícias novidades
O Rec6 é um sistema nacional similar ao internacional Digg.com, ou seja, um clip de notícias que possuí um excelente nível de tópicos. Nos últimos dois dias (mais ou menos, tá? Na verdade eu vi isso ontem, vide a data do post do Bruno, mas considerando a madrugada, etc e tal...) eu tive mais notícias interessantes "que eu não procurei, mas gostei de ter recebido" chegando no meu leitor de feeds do que nas últimas duas semanas.
Só para deixar claro, chamo de "notícias interessantes que eu não procurei, mas gostei de ter recebido" todas aquelas notícias que a eu não pensava que existiam, de fontes de qualidade que eu não conhecia, de pessoas que eu nunca tinha lido. E além dessas notícias novas e de qualidade eu ainda vi as notícias que eu já tinha lido e/ou vi em algum blog, até notícias do meu blog já passaram por lá, mas essas, como dizer, eu já esperava. O que me impressionou não foram as notícias em si, quem lê mais de 350 feeds não é facilmente surpreendido com novidades, mas os excelentes textos de diversos autores (nacionais e internacionais) que eu nunca tinha lido e que eu provavelmente só descobriria depois que alguém "monitorado" fizesse um link para o site deles.
Para dar um exemplo, veja esse link: 30 Social Bookmarks 'Add to' footer links for blogs
Nesse texto tem uma coleção absurda de sistemas 'Add to' para você adicionar no seu blog. Eu estava procurando por isso a dias, mas eu sequer sabia o nome "desses negócios", quero dizer: eu nunca realizaria uma busca decente no google sem conhecer o mínimo do que procuro. O resultado pode ser visto aqui mesmo, ou melhor, no meu blog mesmo (quem estiver lendo do planeta precisa abrir o blog para ver a novidade), acrescentei nele uma barra para facilitar a vida de quem quiser adicionar o conteúdo desse blog no seu bookmark social ou no seu clip de notícias preferido. E claro, o primeiro da lista (da esquerda para a direita) é o Rec6!
Friday, November 10, 2006
Novell, Microsoft, Software Livre e a Comunidade
O acordo entre a Novell e a Microsoft já não é novidade para ninguém, mas esse é mais um texto que fala sobre isso. Aguardei alguns dias para ver que rumo de algumas coisas tomariam, e a minha conclusão, que segue abaixo, é independente de qualquer mudança no acordo e eu diria, independente até desse tão comentado acordo.
No mundo dos negócios o que vale é a sobrevivência e o lucro. Não há lugar para ideologia o filosofia, mesmo que essas sejam as premissas da sustentabilidade futura do seu modelo de negócios adotado. Isso é fato, e nem a Novell, nem a Microsoft se esqueceram disso. Presumir que a Microsoft virou santa é tão estúpido quanto presumir que a Novell é tola.
A verdade é que parece um negócio. Puro e simples. Se der lucro ótimo, se não der, bem, prejuízo não dará... pelo menos não para a empresa.
A grande perda, nesse caso, é ideológica. O "Software Livre" perde adeptos entre os que não conhecem "a causa". Quero dizer: porque criar o amsn para falar, se existisse suporte do msn oficial no linux ? A causa, o motivo, ou seria melhor escrever "a motivação" do desenvolvimento de tecnologias alternativas livres fica comprometida.
Mas isso é tão ruim assim ? Sim, atrasa, e atrasa muito o desenvolvimento de algumas alternativas. Pode induzir ao péssimo hábito de copiar o que está pronto para evitar reescrever outra alternativa livre, mas esse é apenas parte da visão. O maior problema é a divisão da comunidade. Muitos ótimos programadores podem não estar interessados em trabalhos extras para resolver problemas que já tem solução.
A comunidade de programadores tende a se dividir em duas, não necessariamente do mesmo tamanho (na verdade eu tenho certeza que não serão do mesmo tamanho), mas se dividiram entre as que concordam com a utilização parcial de um código fechado e as que vão querer, de qualquer forma, criar tudo livre. Isso por si só já atrasa tudo.
Nas questões que transcendem a filosofia, nas questões práticas, o acordo é positivo, pelo menos no primeiro momento. Mas o futuro pode ser muito, mas muito perigoso.
Existe sempre a questão: o que é livre hoje pode não ser amanhã, mas o que já foi distribuído como software livre contínua livre sempre, mesmo que a empresa mude de opinião quanto a versão futura dos software. Da mesma forma ocorre com o freeware, hoje grátis, amanhã pode não ser mais grátis, as versões antigas continuam sendo grátis, mas ao contrário do software livre que deixa de ser livre, não é possível criar um fork da solução, ou seja, não será possível criar um desenvolvimento paralelo do software, já que o código nunca esteve aberto !
Agora notem que essa discussão não é nova e nem tem nada haver com a Microsoft ou Novell, ao contrário, ela é a base de toda a luta do "Software Livre", o real motivo de estarmos fazendo essa discussão agora é que o nome Microsoft chama atenção demais. A nVIDIA, ATI, Intel e tantas outras empresas que adotaram o mesmo modelo de adotado pela Microsoft em acordos com distribuições linux, não foram vistos com o mesmo nível de preocupação. Em parte, porque eles vendem hardware e não software, mas a dependência que temos da tecnologia é grande. O que aconteceria se nVIDIA resolvesse cobrar pelos drives para linux ? Ela poderia fazer isso? Não para as placas antigas, ou seja, as já vendidas, para ela poderia parar de introduzir novos recursos. Que alternativas nós teríamos ? O drive genérico, nv. Que é bom, mas se comparado com o oficial da nVIDIA é muito ruim.
Agora notem que isso é uma relação de mão dupla, se a nVIDIA parasse de distribuir os drives, muita gente compraria ATI, que não é boba, e esperaria todo mundo comprar as placas para fazer a mesma coisa que a nVIDIA. Mas elas não vão fazer isso, e sabe porque ? Lucro. O máximo de lucro ocorre com o atual modelo de negócios, perturbar esse modelo de negócios dá prejuízo e ninguém quer prejuízo.
Por outro lado, quando a relação é feita entre empresas de softwares tudo fica muito mais evidente. Fica mais claro. Os possíveis problemas são muito mais fáceis de se perceber. Mas da mesma forma que no caso anterior, existe um equilíbrio. Um equilíbrio que não pode ser quebrado, afinal o lucro é o que interessa a uma empresa. A nível usuário e economia, nada muda, a nível filosofia e desenvolvimento, pode mudar.
Ciente de que nem todas as pessoas entendem e/ou concordam com essa visão, eu me reservo no direito de considerar o acordo da Miscrosoft e a Novell prejudicial ao Software Livre, pois considero que teremos mais prejuízos do que lucro a nível filosófico. Mas e daí ? As empresas não vão voltar atrás por causa de uma simples opinião de um usuários que não usa windows e nem usa suse, é talvez não. Mas isso não importa.
O jogo consiste em continuar com a mesma sede de conhecimento e desenvolvimento de alternativas livres independentes das soluções proprietárias que existam. Eu não sou do tipo que diz: parem de usar software proprietário. Eu sou do tipo que diz: use software livre. O que pode parecer a mesma coisa no primeiro momento, é diferente, no primeiro desclassificamos uma categoria inteira de software, no segundo buscamos alternativas, se elas não existem, bem usemos o proprietário, mas sem esquecer que devemos buscar a alternativa livre.
A busca pelo conhecimento define a evolução, não serão os acordos comerciais que farão a diferença, mas o comportamento da comunidade, como um todo, frente a dúvida entre o código fácil e o código livre.
Technorati Tags: opinião software+livre
No mundo dos negócios o que vale é a sobrevivência e o lucro. Não há lugar para ideologia o filosofia, mesmo que essas sejam as premissas da sustentabilidade futura do seu modelo de negócios adotado. Isso é fato, e nem a Novell, nem a Microsoft se esqueceram disso. Presumir que a Microsoft virou santa é tão estúpido quanto presumir que a Novell é tola.
A verdade é que parece um negócio. Puro e simples. Se der lucro ótimo, se não der, bem, prejuízo não dará... pelo menos não para a empresa.
A grande perda, nesse caso, é ideológica. O "Software Livre" perde adeptos entre os que não conhecem "a causa". Quero dizer: porque criar o amsn para falar, se existisse suporte do msn oficial no linux ? A causa, o motivo, ou seria melhor escrever "a motivação" do desenvolvimento de tecnologias alternativas livres fica comprometida.
Mas isso é tão ruim assim ? Sim, atrasa, e atrasa muito o desenvolvimento de algumas alternativas. Pode induzir ao péssimo hábito de copiar o que está pronto para evitar reescrever outra alternativa livre, mas esse é apenas parte da visão. O maior problema é a divisão da comunidade. Muitos ótimos programadores podem não estar interessados em trabalhos extras para resolver problemas que já tem solução.
A comunidade de programadores tende a se dividir em duas, não necessariamente do mesmo tamanho (na verdade eu tenho certeza que não serão do mesmo tamanho), mas se dividiram entre as que concordam com a utilização parcial de um código fechado e as que vão querer, de qualquer forma, criar tudo livre. Isso por si só já atrasa tudo.
Nas questões que transcendem a filosofia, nas questões práticas, o acordo é positivo, pelo menos no primeiro momento. Mas o futuro pode ser muito, mas muito perigoso.
Existe sempre a questão: o que é livre hoje pode não ser amanhã, mas o que já foi distribuído como software livre contínua livre sempre, mesmo que a empresa mude de opinião quanto a versão futura dos software. Da mesma forma ocorre com o freeware, hoje grátis, amanhã pode não ser mais grátis, as versões antigas continuam sendo grátis, mas ao contrário do software livre que deixa de ser livre, não é possível criar um fork da solução, ou seja, não será possível criar um desenvolvimento paralelo do software, já que o código nunca esteve aberto !
Agora notem que essa discussão não é nova e nem tem nada haver com a Microsoft ou Novell, ao contrário, ela é a base de toda a luta do "Software Livre", o real motivo de estarmos fazendo essa discussão agora é que o nome Microsoft chama atenção demais. A nVIDIA, ATI, Intel e tantas outras empresas que adotaram o mesmo modelo de adotado pela Microsoft em acordos com distribuições linux, não foram vistos com o mesmo nível de preocupação. Em parte, porque eles vendem hardware e não software, mas a dependência que temos da tecnologia é grande. O que aconteceria se nVIDIA resolvesse cobrar pelos drives para linux ? Ela poderia fazer isso? Não para as placas antigas, ou seja, as já vendidas, para ela poderia parar de introduzir novos recursos. Que alternativas nós teríamos ? O drive genérico, nv. Que é bom, mas se comparado com o oficial da nVIDIA é muito ruim.
Agora notem que isso é uma relação de mão dupla, se a nVIDIA parasse de distribuir os drives, muita gente compraria ATI, que não é boba, e esperaria todo mundo comprar as placas para fazer a mesma coisa que a nVIDIA. Mas elas não vão fazer isso, e sabe porque ? Lucro. O máximo de lucro ocorre com o atual modelo de negócios, perturbar esse modelo de negócios dá prejuízo e ninguém quer prejuízo.
Por outro lado, quando a relação é feita entre empresas de softwares tudo fica muito mais evidente. Fica mais claro. Os possíveis problemas são muito mais fáceis de se perceber. Mas da mesma forma que no caso anterior, existe um equilíbrio. Um equilíbrio que não pode ser quebrado, afinal o lucro é o que interessa a uma empresa. A nível usuário e economia, nada muda, a nível filosofia e desenvolvimento, pode mudar.
Ciente de que nem todas as pessoas entendem e/ou concordam com essa visão, eu me reservo no direito de considerar o acordo da Miscrosoft e a Novell prejudicial ao Software Livre, pois considero que teremos mais prejuízos do que lucro a nível filosófico. Mas e daí ? As empresas não vão voltar atrás por causa de uma simples opinião de um usuários que não usa windows e nem usa suse, é talvez não. Mas isso não importa.
O jogo consiste em continuar com a mesma sede de conhecimento e desenvolvimento de alternativas livres independentes das soluções proprietárias que existam. Eu não sou do tipo que diz: parem de usar software proprietário. Eu sou do tipo que diz: use software livre. O que pode parecer a mesma coisa no primeiro momento, é diferente, no primeiro desclassificamos uma categoria inteira de software, no segundo buscamos alternativas, se elas não existem, bem usemos o proprietário, mas sem esquecer que devemos buscar a alternativa livre.
A busca pelo conhecimento define a evolução, não serão os acordos comerciais que farão a diferença, mas o comportamento da comunidade, como um todo, frente a dúvida entre o código fácil e o código livre.
Melhorias no GMail
Acredito que a maioria já saiba ou já tenha percebido. Mas recentes melhorias no GMail incrementam ainda mais esse que já é considerado por muitos o melhor cliente de e-mail da atualidade, superando, inclusive, os clientes de desktop, tá certo, ele ainda não é melhor pela maioria, mas deixa só sair a pesquisa dos favoritos de 2006 para ver como ele vai estar bem cotado (lembrando que a votação vai até amanhã).
Agora é possível administrar melhor os e-mails deletando mensagens intermediárias de uma conversa. Além de grandes melhorais na forma de fazer um "reply" da mensagem, a melhoria que mais me chamou atenção é clareza invejável do cabeçalho, as informações são as mesmas, mas a forma com que ele está escrito melhorou significativamente.
Technorati Tags: gmail e-mail web2.0
Agora é possível administrar melhor os e-mails deletando mensagens intermediárias de uma conversa. Além de grandes melhorais na forma de fazer um "reply" da mensagem, a melhoria que mais me chamou atenção é clareza invejável do cabeçalho, as informações são as mesmas, mas a forma com que ele está escrito melhorou significativamente.
Sunday, November 05, 2006
Usando o Google Brasil nas buscas com o Firefox
Quem usa a barra de buscas do firefox sabe que ao digitar alguma coisa lá no plugin do google, a busca é feita no Google Internacional. O principal incômodo desse problema é que não aparece a opção de restringir a busca na língua portuguesa. Uma forma bem eficiente de resolver isso é editar o plugin de busca do firefox manualmente.
Para isso, e considerando ${FIREFOX} o diretório principal de instalação, edite o arquivo:
(*) O src foi substituído pelo xml na versão 2.0, existe muita vantagem nisso, mas para os desenvolvedores de plugins de busca, entre outras conseqüências, temos que não é mais preciso ter dois arquivos para o plugin de busca, o src e o ícone, basta o xml, o ícone fica implícito no xml. A versão antiga do plugin é compatível com o Firefox atual.
(**) Não sabe onde o Firefox está instalado ? Bem, use o locate, digite no terminal, como usuário comum: "locate google.xml" ou "locate google.src". Na saída do comando, você receberá o caminho completo e exato do arquivo que iremos editar, esse caminho é sempre do tipo: ${FIREFOX}/searchplugins/google.*. O detalhe é que o ${FIREFOX} pode ser qualquer caminho, dependendo da distribuição ou da ação prévia de um usuário.
Technorati Tags: firefox tips
Para isso, e considerando ${FIREFOX} o diretório principal de instalação, edite o arquivo:
- ${FIREFOX}/searchplugins/google.xml para o Firefox 2.0 ou
- ${FIREFOX}/searchplugins/google.src para versões anteriores(*).
sudo gedit /opt/firefox/searchplugins/google.xmlDentro deste arquivo, substitua o termo
"http://www.google.com/search"pelo termo
"http://www.google.com.br/search"ou seja, acrescente o .br e (re)inicie o Firefox. A mesma linha e a mesma substituição deve ser feita se estiver em versões anteriores (os .src).
(*) O src foi substituído pelo xml na versão 2.0, existe muita vantagem nisso, mas para os desenvolvedores de plugins de busca, entre outras conseqüências, temos que não é mais preciso ter dois arquivos para o plugin de busca, o src e o ícone, basta o xml, o ícone fica implícito no xml. A versão antiga do plugin é compatível com o Firefox atual.
(**) Não sabe onde o Firefox está instalado ? Bem, use o locate, digite no terminal, como usuário comum: "locate google.xml" ou "locate google.src". Na saída do comando, você receberá o caminho completo e exato do arquivo que iremos editar, esse caminho é sempre do tipo: ${FIREFOX}/searchplugins/google.*. O detalhe é que o ${FIREFOX} pode ser qualquer caminho, dependendo da distribuição ou da ação prévia de um usuário.
Você monitora os logs do sistema ?
Todos os seus logs vão, por padrão, para o diretório /var/log/ ou em subdiretórios deste. Minha pergunta do título: "Você cuida dos seus logs ? está relacionada a um erro que cometi. Eu esqueci dos logs.
Esquecer dos logs pode não ter nada demais, mas dependendo do que tenha instalado no computador, do número de usuários ou do tempo que levou sem se lembrar desses arquivos, eles podem consumir um espaço absurdo. No meu caso, além do apache, MySQL e outros servidores, também tem o Snort.
Bom, eu quero chegar na surpresa que tive ao abrir hoje o diretório de logs: 7 GB de espaço consumido. Dos quais 6 GB eram apenas do snort. Isso remete a um fato: Eu não precisava desses logs! Sim, porque se eu tivesse precisado eu teria descoberto o tamanho exagerado do diretório a muito mais tempo.
Isso aconteceu por dois motivos, o primeiro é que eu não fazia uma limpeza nos meus logs antigos a cerca de 5 meses e o segundo é que eu "errei" nas configurações do snort, mandei ele anotar tudo. De qualquer forma, mesmo que eu não tivesse "errado" nas configurações do snort, eu teria cerca de 1 GB de logs antigos no meu computador gerados em mais ou menos 5 meses.
Bom, isso fica como alerta aos novos usuários, especialmente para quem acaba de vir do windows onde esse conceito de log simplesmente não existe a nível de usuário comum.
Mas como definir o que é velho o suficiente para ser deletado ? Eu simplifico muito essa análise eliminando apenas os logs compactados, ou seja, todos os arquivos que estiverem sob diretório e subdiretórios de /var/log/ e tiver a extensão ".gz".
É seguro remover esses logs compactados ? Sim, a nível técnico é seguro. Em outros níveis, existem outros aspectos as serem considerados, exemplo disso é quem hospeda uma página na internet no computador pessoal. Você deve manter os logs de acesso a sua página na internet hospedada localmente no seu computador. Se você tiver algum problema, o número de ip poderá ser utilizado contra quem te causou problemas. No geral, quem tem um servidor para acesso público deve manter os logs desse acesso, mas a nível de usuário comum, de Desktop, essas considerações adicionais não são aplicáveis.
E quanto aos outros logs ? Os outros logs, ou seja, os logs não compactados, são os mais recentes e podem ou não conter informações importantes. Minha recomendação é que se não sabe, não delete. O fato é que existe sempre dois logs muito importantes para cada serviço no computador, o atual e o anterior. Eles serão seus melhores amigos na hora de descobrir o que deu errado. De qualquer forma é importante que jamais delete os logs atualmente em uso pelo sistema.
Technorati Tags: log linux
Esquecer dos logs pode não ter nada demais, mas dependendo do que tenha instalado no computador, do número de usuários ou do tempo que levou sem se lembrar desses arquivos, eles podem consumir um espaço absurdo. No meu caso, além do apache, MySQL e outros servidores, também tem o Snort.
Bom, eu quero chegar na surpresa que tive ao abrir hoje o diretório de logs: 7 GB de espaço consumido. Dos quais 6 GB eram apenas do snort. Isso remete a um fato: Eu não precisava desses logs! Sim, porque se eu tivesse precisado eu teria descoberto o tamanho exagerado do diretório a muito mais tempo.
Isso aconteceu por dois motivos, o primeiro é que eu não fazia uma limpeza nos meus logs antigos a cerca de 5 meses e o segundo é que eu "errei" nas configurações do snort, mandei ele anotar tudo. De qualquer forma, mesmo que eu não tivesse "errado" nas configurações do snort, eu teria cerca de 1 GB de logs antigos no meu computador gerados em mais ou menos 5 meses.
Bom, isso fica como alerta aos novos usuários, especialmente para quem acaba de vir do windows onde esse conceito de log simplesmente não existe a nível de usuário comum.
Mas como definir o que é velho o suficiente para ser deletado ? Eu simplifico muito essa análise eliminando apenas os logs compactados, ou seja, todos os arquivos que estiverem sob diretório e subdiretórios de /var/log/ e tiver a extensão ".gz".
É seguro remover esses logs compactados ? Sim, a nível técnico é seguro. Em outros níveis, existem outros aspectos as serem considerados, exemplo disso é quem hospeda uma página na internet no computador pessoal. Você deve manter os logs de acesso a sua página na internet hospedada localmente no seu computador. Se você tiver algum problema, o número de ip poderá ser utilizado contra quem te causou problemas. No geral, quem tem um servidor para acesso público deve manter os logs desse acesso, mas a nível de usuário comum, de Desktop, essas considerações adicionais não são aplicáveis.
E quanto aos outros logs ? Os outros logs, ou seja, os logs não compactados, são os mais recentes e podem ou não conter informações importantes. Minha recomendação é que se não sabe, não delete. O fato é que existe sempre dois logs muito importantes para cada serviço no computador, o atual e o anterior. Eles serão seus melhores amigos na hora de descobrir o que deu errado. De qualquer forma é importante que jamais delete os logs atualmente em uso pelo sistema.
Saturday, November 04, 2006
Descobrindo o código UUID de uma partição do HD
Essa deve ser mais do que velha, mas eu descobri isso ontem e foi por necessidade, então ...
Para descobrir o código UUID de uma partição do HD, podemos usar o programa vol_id.
Para executá-lo, basta executar no terminal:
sudo vol_id -u /dev/hda1
onde o "a" e o "1" devem ser substituidos de acordo com seu HD/partição [quer saber mais sobre partições do hd ? Leia esse artigo]. A opção "-u" serve para que seja mostrado apenas o UUID da partição, para informações mais detalhadas, pode-se usar:
sudo vol_id /dev/hda1
ou seja, o mesmo comando sem a opção "-u".
Mas porque precisamos disso ? Na verdade não precisamos, mas o Ubuntu Edgy Eft passou a utilizar o UUID na montagem das partições do sistema. Se não quiser manter esse padrão e usar o tracional [pode ver aqui também], não tem problema, mas se quiser, mais cedo ou mais tarde pode precisar desse comando.
Se quiser saber mais sobre a novidade do UUID no Ubuntu Edgy Eft, leia esse post: Novidade no edgy: UUID no fstab e menu.lst do grub
Technorati Tags: linux uuid hd
Para descobrir o código UUID de uma partição do HD, podemos usar o programa vol_id.
Para executá-lo, basta executar no terminal:
sudo vol_id -u /dev/hda1
onde o "a" e o "1" devem ser substituidos de acordo com seu HD/partição [quer saber mais sobre partições do hd ? Leia esse artigo]. A opção "-u" serve para que seja mostrado apenas o UUID da partição, para informações mais detalhadas, pode-se usar:
sudo vol_id /dev/hda1
ou seja, o mesmo comando sem a opção "-u".
Mas porque precisamos disso ? Na verdade não precisamos, mas o Ubuntu Edgy Eft passou a utilizar o UUID na montagem das partições do sistema. Se não quiser manter esse padrão e usar o tracional [pode ver aqui também], não tem problema, mas se quiser, mais cedo ou mais tarde pode precisar desse comando.
Se quiser saber mais sobre a novidade do UUID no Ubuntu Edgy Eft, leia esse post: Novidade no edgy: UUID no fstab e menu.lst do grub
Friday, November 03, 2006
Meus visitantes! O que posso fazer por você?
Mencionei a algum tempo que eu tinha adicionado o Google Analytics nesse blog [link]. Isso foi no dia 22/09/2006, ou seja, a pouco mais de um mês.
Não tenho como objetivo otimizar lucros, simplesmente pelo fato que não tenho qualquer tipo de propaganda, meu objetivo é escrever melhor. Assim, eu acompanho a estatítica do blog semanalmente.
Bom, vamos aos gráficos!
Primeiro o gráfico que mostra número de visitantes por navegador.

Era de se esperar que nesse blog o número de usuários do Firefox, ou melhor, dos navegadores livres fosse maior que do internet explorer. Agora o número de usuários acessando esse blog através do internet explorer é muito alto. Em mais ou menos um mês, eu tive 633 visitantes únicos que utilizam o internet explorer.
Continuando, temos abaixo o número de visitantes por sistema operacional. Note que eu não discriminei a versão.
O que temos acima é uma amostra do que eu não esperava: O número de usuários do Windows é maior que o número de usuários do Linux. Mas pensando melhor, temos que meditar um pouco sobre isso, é verdade que o número de usuários de windows no mundo é maior que o número de usuários do Linux e é razoável esperar um número relativamente alto de usuários windows nesse blog. Isso permite algumas teorias: ou tem muitos usuários do linux obrigados a usar o windows durante o trabalho ou o número de usuários que usam o windows e buscam informações sobre o linux é alto ou tem muita gente perdida por aqui.
Posso descartar a última opção, isso porque conheço bem as páginas que são lidas, e alguém perdido não passa sequer da primeira página, quanto mais vai a fundo nos tópicos, não vou entrar em detalhes, mas o número de usuários perdidos deve ser bem pequeno. Então ficamos com as duas primeiras e certamente as duas ocorrem.
Agora vamos pensar, todos os usuários do internet explorer, estão, por hipótese, no windows (razoável, não é ?). Logo, mais de 600 visitantes utilizam o windows e o firefox. Oras, pelo meu raciocínio, ou melhor, por hipótese, todos os usuários de linux obrigados a usar o windows durante o trabalho (ou em qualquer outro momento) muito provavelmente usaram o firefox. Assim, nos resta mais de 600 visitantes que estão usando o windows com o internet explorer e buscam informações sobre o linux durante esse mês. E aqui teremos uma hipótese forte, diremos que todos os usuários que acessam o blog através do firefox no windows são usuários do linux quando possível. A hipótese é forte, mas ajuda na compreensão do perfil dos visitantes.
Bem, esse blog não é tão popular assim, tenho uma média de 40 visitantes únicos por dia (atualmente, comecei no google analytics com mais ou menos 10 por dia), supondo uma estatística homogêniea (algo que com certeza não ocorre aqui) temos na média, pelo menos 20 usuários do windows aqui onde mais ou menos 10 usam o internet explorer e, que possivelmente (no mínimo uma boa parcela destes), nunca usaram o Linux ou o Firefox.
Conclusões:
A primeira conclusão é na verdade uma mensagem aos meus visitantes diários que estão usando internet explorer, conheçam o Firefox. Pode até não ser o melhor browser do mundo [nota: eu acho que é melhor], mas é infinitamente superior a qualquer versão do ie. Então, porque utilizar o internet explorer ? O ie é provavelmente o pior software da microsoft, então experimentem o Firefox. Usem o Firefox, redescrubra a web clique aqui e veja como tudo pode melhorar.

Gostaria muito, mas muito mesmo, de ver que o número visitantes usuários do internet explorer cair, mas não que eu esteja mandando esse usuários embora, muito menos porque estou ordenando alguma coisa, não é isso, mas porque o firefox é melhor, e não é melhor por minha causa, mas por causa dele mesmo, não precisa acreditar em mim, usem o Firefox por uma semana e eu duvido que voltaram a utilizar o internet explorer, será a sua opção.
Mas se depois de uma semana usando o Firefox quiser voltar para internet explorer, bem, não sou eu que vou obrigá-lo a alguma coisa, mas faça um favor a todos nós, diga porque não quer o firefox. Ajude a um grupo sério a se tornar o seu favorito. Se tem algo que não te agrada, deixe todo mundo saber o que é. A Mozilla agradecerá, com certeza. E não tenha medo, eu modero todos os comentários desse blog, não permitirei nenhuma ofensa a sua opinão, mesmo quando ela não representar a minha. Não deixe de ajudar a tornar o Firefox o seu preferido.
A segunda conclusão é também uma autocrítica, é que devo ser mais detalhista nos meus passos básicos. Está certo que alguns passos não são tão básicos, mas quando mencionar os primeiros passos devo passar detalhadamente, muita gente parece vir a esse blog do windows para estudar soluções que só podem ser aplicadas no linux, sei disso por causa das páginas visitadas. E isso prova uma coisa: a informação básica não deve estar tão fácil de achar assim, como nós, usuários do linux, gostamos de acreditar.
Um lugar que eu recomendo a todos os é o Guia Foca GNU/Linux, esse guia aborda do básico ao avançado e existe nas versões html, txt e pdf. Se por outro lado, precisa de um guia para um "sistema visual", como o KDE ou Gnome temos a documentação do (K)Ubuntu, que pode ser encontrada aqui. O foco é o Ubuntu, mas básico é básico, boa parte do que aprender com esse guia servirá para muitas distribuições.
Uma coisa que eu sempre pensei, não seríamos muito repetivos ? Dizemos a cada post colocarmos as mesmas coisas para lembrar os usuários do que estamos querendo, quero dizer, porque digitar sudo apt-get se podemos colocar apenas apt-get no texto, afinal todo mundo sabe que apt-get é para superusuário, certo ? Bem, pelo que vejo nem todo mundo. Ser repetitivo parece ser uma necessidade não uma opção, isso é uma forte autocrítica, eu não pensava assim, e se você também não pensa(va) faça uma análise similar no seu blog ! Veja o perfil dos seus usuários talvez no seu caso seja diferente, mas se não for devemos, sim, rever nossas posições.
E por fim, o surgimento de um movimento (aliás, sabidamente nem tão novo assim, eu é que estou registrando isso agora) de usuários de computador atrás de soluções que atendam suas próprias demandas em alternativa as solução que são atualmente utilizadas por eles. Os motivos que podem induzir aos usuários buscar outras soluções podem ser diversos e eu não vou listá-los aqui, mas a pergunta que fica é: Estaremos prontos para receber essa nova turma que talvez não esteja tão filosoficamente conectados ao mundo opensource ?
Nota Final
Primeiro devo me desculpar pelo tamanho do post, achei justificativo um post desse tamanho para esse assunto. Segundo, talvez as minhas conclusões sejam prematuras, talvez não seja esse, afinal, o perfil dos meus visitantes e eu precise de mais "pontos" para uma melhor representatividade estatística. Mas uma coisa eu percebi: minhas observações somente agregam benefícios, então, se estão ou não corretas, pode nesse caso, não ser o mais importante. Caso leia esse blog e não concorde com nada do eu escrevi, deixe-me saber! Afinal, eu tive esse trabalho todo só por você!
Technorati Tags: opinião estatística blog linux windows perfil
Não tenho como objetivo otimizar lucros, simplesmente pelo fato que não tenho qualquer tipo de propaganda, meu objetivo é escrever melhor. Assim, eu acompanho a estatítica do blog semanalmente.
Bom, vamos aos gráficos!
Primeiro o gráfico que mostra número de visitantes por navegador.
Era de se esperar que nesse blog o número de usuários do Firefox, ou melhor, dos navegadores livres fosse maior que do internet explorer. Agora o número de usuários acessando esse blog através do internet explorer é muito alto. Em mais ou menos um mês, eu tive 633 visitantes únicos que utilizam o internet explorer.
Continuando, temos abaixo o número de visitantes por sistema operacional. Note que eu não discriminei a versão.
O que temos acima é uma amostra do que eu não esperava: O número de usuários do Windows é maior que o número de usuários do Linux. Mas pensando melhor, temos que meditar um pouco sobre isso, é verdade que o número de usuários de windows no mundo é maior que o número de usuários do Linux e é razoável esperar um número relativamente alto de usuários windows nesse blog. Isso permite algumas teorias: ou tem muitos usuários do linux obrigados a usar o windows durante o trabalho ou o número de usuários que usam o windows e buscam informações sobre o linux é alto ou tem muita gente perdida por aqui.
Posso descartar a última opção, isso porque conheço bem as páginas que são lidas, e alguém perdido não passa sequer da primeira página, quanto mais vai a fundo nos tópicos, não vou entrar em detalhes, mas o número de usuários perdidos deve ser bem pequeno. Então ficamos com as duas primeiras e certamente as duas ocorrem.
Agora vamos pensar, todos os usuários do internet explorer, estão, por hipótese, no windows (razoável, não é ?). Logo, mais de 600 visitantes utilizam o windows e o firefox. Oras, pelo meu raciocínio, ou melhor, por hipótese, todos os usuários de linux obrigados a usar o windows durante o trabalho (ou em qualquer outro momento) muito provavelmente usaram o firefox. Assim, nos resta mais de 600 visitantes que estão usando o windows com o internet explorer e buscam informações sobre o linux durante esse mês. E aqui teremos uma hipótese forte, diremos que todos os usuários que acessam o blog através do firefox no windows são usuários do linux quando possível. A hipótese é forte, mas ajuda na compreensão do perfil dos visitantes.
Bem, esse blog não é tão popular assim, tenho uma média de 40 visitantes únicos por dia (atualmente, comecei no google analytics com mais ou menos 10 por dia), supondo uma estatística homogêniea (algo que com certeza não ocorre aqui) temos na média, pelo menos 20 usuários do windows aqui onde mais ou menos 10 usam o internet explorer e, que possivelmente (no mínimo uma boa parcela destes), nunca usaram o Linux ou o Firefox.
Conclusões:
A primeira conclusão é na verdade uma mensagem aos meus visitantes diários que estão usando internet explorer, conheçam o Firefox. Pode até não ser o melhor browser do mundo [nota: eu acho que é melhor], mas é infinitamente superior a qualquer versão do ie. Então, porque utilizar o internet explorer ? O ie é provavelmente o pior software da microsoft, então experimentem o Firefox. Usem o Firefox, redescrubra a web clique aqui e veja como tudo pode melhorar.
Gostaria muito, mas muito mesmo, de ver que o número visitantes usuários do internet explorer cair, mas não que eu esteja mandando esse usuários embora, muito menos porque estou ordenando alguma coisa, não é isso, mas porque o firefox é melhor, e não é melhor por minha causa, mas por causa dele mesmo, não precisa acreditar em mim, usem o Firefox por uma semana e eu duvido que voltaram a utilizar o internet explorer, será a sua opção.
Mas se depois de uma semana usando o Firefox quiser voltar para internet explorer, bem, não sou eu que vou obrigá-lo a alguma coisa, mas faça um favor a todos nós, diga porque não quer o firefox. Ajude a um grupo sério a se tornar o seu favorito. Se tem algo que não te agrada, deixe todo mundo saber o que é. A Mozilla agradecerá, com certeza. E não tenha medo, eu modero todos os comentários desse blog, não permitirei nenhuma ofensa a sua opinão, mesmo quando ela não representar a minha. Não deixe de ajudar a tornar o Firefox o seu preferido.
A segunda conclusão é também uma autocrítica, é que devo ser mais detalhista nos meus passos básicos. Está certo que alguns passos não são tão básicos, mas quando mencionar os primeiros passos devo passar detalhadamente, muita gente parece vir a esse blog do windows para estudar soluções que só podem ser aplicadas no linux, sei disso por causa das páginas visitadas. E isso prova uma coisa: a informação básica não deve estar tão fácil de achar assim, como nós, usuários do linux, gostamos de acreditar.
Um lugar que eu recomendo a todos os é o Guia Foca GNU/Linux, esse guia aborda do básico ao avançado e existe nas versões html, txt e pdf. Se por outro lado, precisa de um guia para um "sistema visual", como o KDE ou Gnome temos a documentação do (K)Ubuntu, que pode ser encontrada aqui. O foco é o Ubuntu, mas básico é básico, boa parte do que aprender com esse guia servirá para muitas distribuições.
Uma coisa que eu sempre pensei, não seríamos muito repetivos ? Dizemos a cada post colocarmos as mesmas coisas para lembrar os usuários do que estamos querendo, quero dizer, porque digitar sudo apt-get se podemos colocar apenas apt-get no texto, afinal todo mundo sabe que apt-get é para superusuário, certo ? Bem, pelo que vejo nem todo mundo. Ser repetitivo parece ser uma necessidade não uma opção, isso é uma forte autocrítica, eu não pensava assim, e se você também não pensa(va) faça uma análise similar no seu blog ! Veja o perfil dos seus usuários talvez no seu caso seja diferente, mas se não for devemos, sim, rever nossas posições.
E por fim, o surgimento de um movimento (aliás, sabidamente nem tão novo assim, eu é que estou registrando isso agora) de usuários de computador atrás de soluções que atendam suas próprias demandas em alternativa as solução que são atualmente utilizadas por eles. Os motivos que podem induzir aos usuários buscar outras soluções podem ser diversos e eu não vou listá-los aqui, mas a pergunta que fica é: Estaremos prontos para receber essa nova turma que talvez não esteja tão filosoficamente conectados ao mundo opensource ?
Nota Final
Primeiro devo me desculpar pelo tamanho do post, achei justificativo um post desse tamanho para esse assunto. Segundo, talvez as minhas conclusões sejam prematuras, talvez não seja esse, afinal, o perfil dos meus visitantes e eu precise de mais "pontos" para uma melhor representatividade estatística. Mas uma coisa eu percebi: minhas observações somente agregam benefícios, então, se estão ou não corretas, pode nesse caso, não ser o mais importante. Caso leia esse blog e não concorde com nada do eu escrevi, deixe-me saber! Afinal, eu tive esse trabalho todo só por você!
Thursday, November 02, 2006
SuperKaramba: Informações da CPU
Esse será um post relativamente rápido. Com apenas um conceito: como obter informações do uso da CPU. Um pequeno tema completo está abaixo.
Esse sensor existe para acompanhar o uso do processador. A linha que o define acima é a seguinte:
No próximo post veremos como obter informações da memória e também teremos uma saída visual na forma de texto. Os textos posteriores terão como foco a criação de gráficos dinâmicos. Esse conceitos de gráficos são muito úteis para serem utilizados também com os sensores de uso de CPU e memória, que são este e o próximo post.
Technorati Tags: superkarmba tema
karamba x=160 y=350 w=200 h=65 interval=1000 locked=trueSe olhar bem, verá que usamos dois sensores ao longo do tema, o primeiro, já comentado, o program, que aqui executa comandos que permitem identificar o processador, a freqüência e a memória cache; o segundo sensor é novo, e o nome é: cpu.
image x=0 y=10 path="icons/ksim_cpu.png"
# Obtendo o modelo da CPU
text x=50 y=1 sensor=program program="cat /proc/cpuinfo | grep 'model name' | sed -e 's/.*: //'"
# Informações do uso de CPU
text x=50 y=22 value="CPU:"
text x=90 y=22 sensor=cpu format="%v%" interval=1000
# Informações da freqüência da CPU
text x=50 y=32 value="MHz:"
text x=90 y=32 sensor=program program="cat /proc/cpuinfo | grep 'cpu MHz' | sed -e 's/.*: //'"
# Obtendo o tamanho da memória cache da CPU
text x=50 y=42 value="Cache:" fontsize=9 font="Cure"
text x=90 y=42 sensor=program program="cat /proc/cpuinfo | grep 'cache size' | sed -e 's/.*: //'"
Esse sensor existe para acompanhar o uso do processador. A linha que o define acima é a seguinte:
text x=90 y=22 sensor=cpu format="%v%" interval=1000Apesar de ter outros formatos de saída, o mais útil é o "%v%" que fornece o uso da CPU. Outras opções fornecem o uso apenas para questões do sistema, ou apenas do usuário corrente, mas esse é o que mais importa em 90 % dos casos. Esse sensor também suporta múltiplos processadores. Mas informações sobre ele pode ser encontrada aqui, é logo o primeiro item.
No próximo post veremos como obter informações da memória e também teremos uma saída visual na forma de texto. Os textos posteriores terão como foco a criação de gráficos dinâmicos. Esse conceitos de gráficos são muito úteis para serem utilizados também com os sensores de uso de CPU e memória, que são este e o próximo post.
Wednesday, November 01, 2006
Superkaramba: time e uptime
Dando continuidade a série, esse tópico abordará formas de usar alguns sensores simples que são utilizados para apresentar a hora e o tempo que o computador está ligado.
O código completo vai abaixo. Eu usei o ícone karm.png, que é o ícone do kalarm, ele é bem representativo tema.
O uptime fornece o tempo que seu computador está ligado. No caso, o formato (format) detalha quantos dias, %dd, e quantas horas com seus minutos, %H:%M. Os dois pontos e os espaço não são interpretados. De forma que lembra a formatação do comando "date".
No caso do time este é utilizado para duas saídas diferentes. Na linha,
Na outra linha, temos
O poder desses dois sensores depende do conhecimento que se tem a respeito de suas opções de formatação. A lista de opções está abaixo. Eu não pretendo traduzir a lista de opções de todos os sensores, mas esse caso é especial, pois o uso apropriado do sensor depende exclusivamente do conhecimento preciso dessas opções, por si só, a lista entediante de ser lida, são apenas opções de formatação será muito mais útil quando quiser encontrar uma forma específica de escrever a formatação do seu tema.
Opções de formatação do sensor time
Formato para escrever os dias
Formato para escrever os meses
Exemplos de formatos (assumindo Terça, 31 Out 2006 23:30:09.051):
Technorati Tags: superkaramba tema
O código completo vai abaixo. Eu usei o ícone karm.png, que é o ícone do kalarm, ele é bem representativo tema.
karamba x=160 y=350 w=200 h=50 interval=1000 locked=trueA única novidade desse código acima são os valores atribuídos a "sensor", que no caso são: uptime e time.
image x=0 y=0 path="icons/karm.png"
# Informação da hora
text x=50 y=5 value="Uptime:"
text x=90 y=5 sensor=uptime format="%dd %H:%M"
text x=50 y=15 value="Hora:"
text x=90 y=15 sensor=time format="hh:mm:ss" interval=1000
# Data
text x=50 y=25 value="Data:"
text x=90 y=25 sensor=time format="ddd, dd/MMM/yyyy"
O uptime fornece o tempo que seu computador está ligado. No caso, o formato (format) detalha quantos dias, %dd, e quantas horas com seus minutos, %H:%M. Os dois pontos e os espaço não são interpretados. De forma que lembra a formatação do comando "date".
No caso do time este é utilizado para duas saídas diferentes. Na linha,
text x=90 y=15 sensor=time format="hh:mm:ss" interval=1000Temos uma saída de "hora atual", o formato é hora, minuto e segundo, separados pelos dois pontos, que não é interpretado. Note a sutileza do interval=1000, isso assegura que a hora será atualizada na tela em cada segundo.
Na outra linha, temos
text x=90 y=25 sensor=time format="ddd, dd/MMM/yyyy"Essa linha informa o dia atual, no formato tipo: "Qua, 01/Nov/2006".
O poder desses dois sensores depende do conhecimento que se tem a respeito de suas opções de formatação. A lista de opções está abaixo. Eu não pretendo traduzir a lista de opções de todos os sensores, mas esse caso é especial, pois o uso apropriado do sensor depende exclusivamente do conhecimento preciso dessas opções, por si só, a lista entediante de ser lida, são apenas opções de formatação será muito mais útil quando quiser encontrar uma forma específica de escrever a formatação do seu tema.
Opções de formatação do sensor time
Formato para escrever os dias
- d - Dia em formato numérico sem um zero na frente (ou seja, 1-31).
- dd - Com um zero na frente (ou seja, 01-31).
- ddd - Nome do dia da semana abreviado (ou seja, 'Seg'..'Dom').
- dddd - Nome do dia da semana sem abreviação (ou seja, 'Segunda'..'Domingo').
Formato para escrever os meses
- M ou MM - meses numericamente (1-12) ou (01-12).
- MMM - Abreviando o nome do mês (Ex. 'Jan').
- MMMM - Nome por extenso (Ex. 'Janeiro').
- yy - ano com dois digítos (00-99).
- yyyy - ano com quatro dígitos (1752-8000).
- Formato para escrever as horas: h ou hh
- Formato para escrever os minutos: m ou mm
- Formato para escrever os segundos: s ou ss
- Formato para escrever os milisegundos: z ou zzz
- Usando o am/pm. AP - usa AM/PM e ap - usa am/pm.
Exemplos de formatos (assumindo Terça, 31 Out 2006 23:30:09.051):
- format="dd.MM.yyyy" -> 31.10.2006
- format="ddd MMMM d yy" -> Ter Out 31 06
- format="hh:mm:ss.zzz" -> 23:30:09.051
- format="h:m:s ap" -> 11:30:9: pm
- %d - Dias.
- %h - Horas.
- %m - Minutos.
- %s - Segundos.
- %H - Hora com a possibilidade do zero na frente.
- %M - Minutos com a possibilidade do zero na frente.
- %S - Segundos com a possibilidade do zero na frente.
- default: format="%dd %h:%M"
Subscribe to:
Posts (Atom)
